On Path to Multimodal Generalist:
General-Level and General-Bench
Does higher end-task performance simply indicate stronger multimodal generalists, closer to AGI?
NO! But SYNERGY does!
At current stage, most MLLMs largely rely on LLMs' language intelligence to approximate multimodal reasoning, merely extending linguistic capabilities to assist multimodal tasks. While LLMs (e.g., GPT series) show synergy within language domains, most MLLMs still fail to achieve such synergy across modalities and tasks. We argue that true progress toward AGI hinges on the synergy effect—where knowledge gained in one modality or task transfers and enhances performance in others, promoting mutual improvement through interconnected learning.
In this project, we introduce General-Level, a novel evaluation framework for multimodal generalists, inspired by tiered evaluation used in autonomous driving. General-Level categorize models’ intelligence levels by assessing their level of synergy across comprehension and generation tasks, as well as across multimodal interactions.
(* synergy can be seen as a form of generalizability—where knowledge from one modality or task transfers to others, enabling mutual improvement in between.)
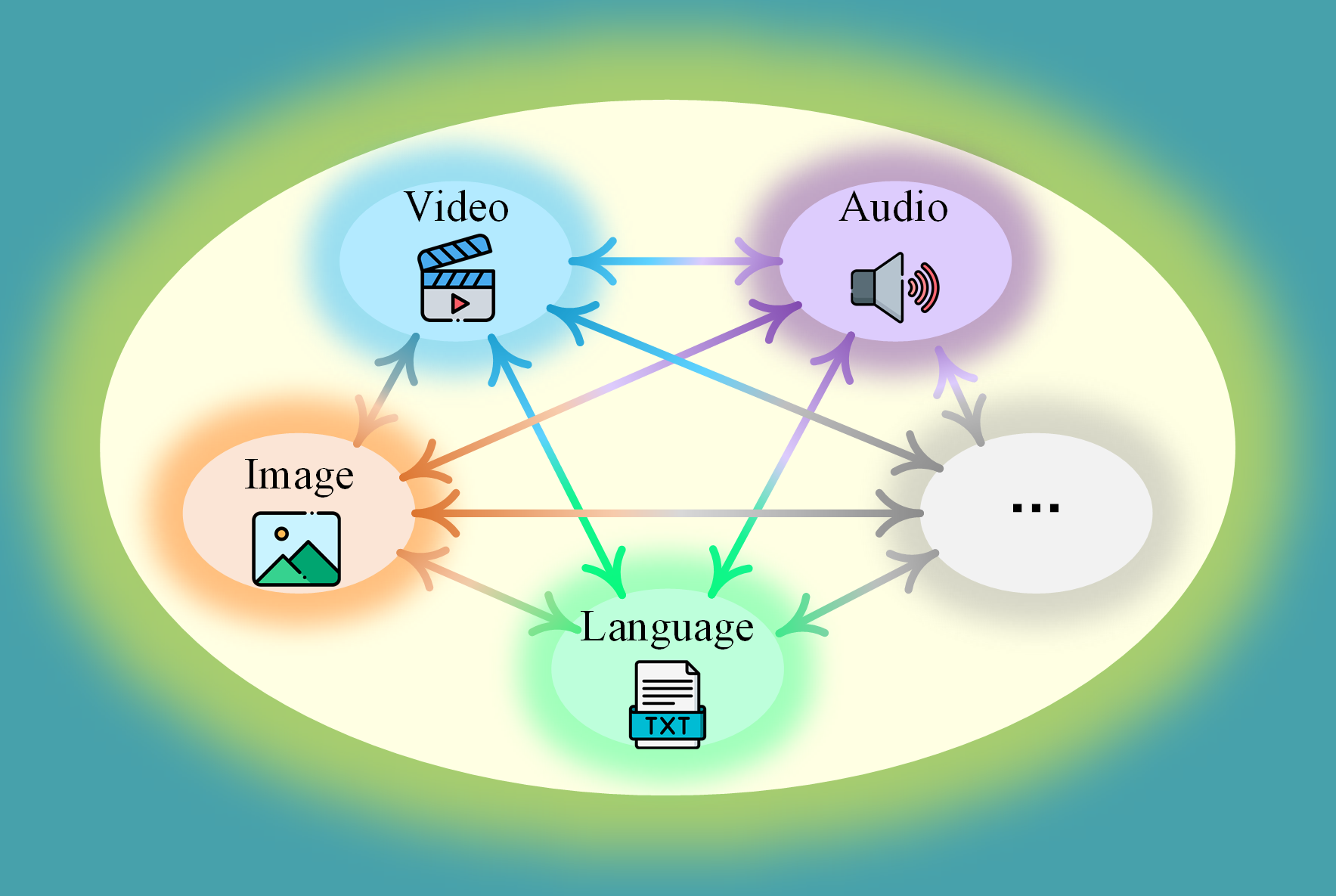
Ultimate Goal: Achieving total synergy across any modalities, any functions/tasks for Multimodal General Intelligence, i.e., the multimodal ChatGPT moment.
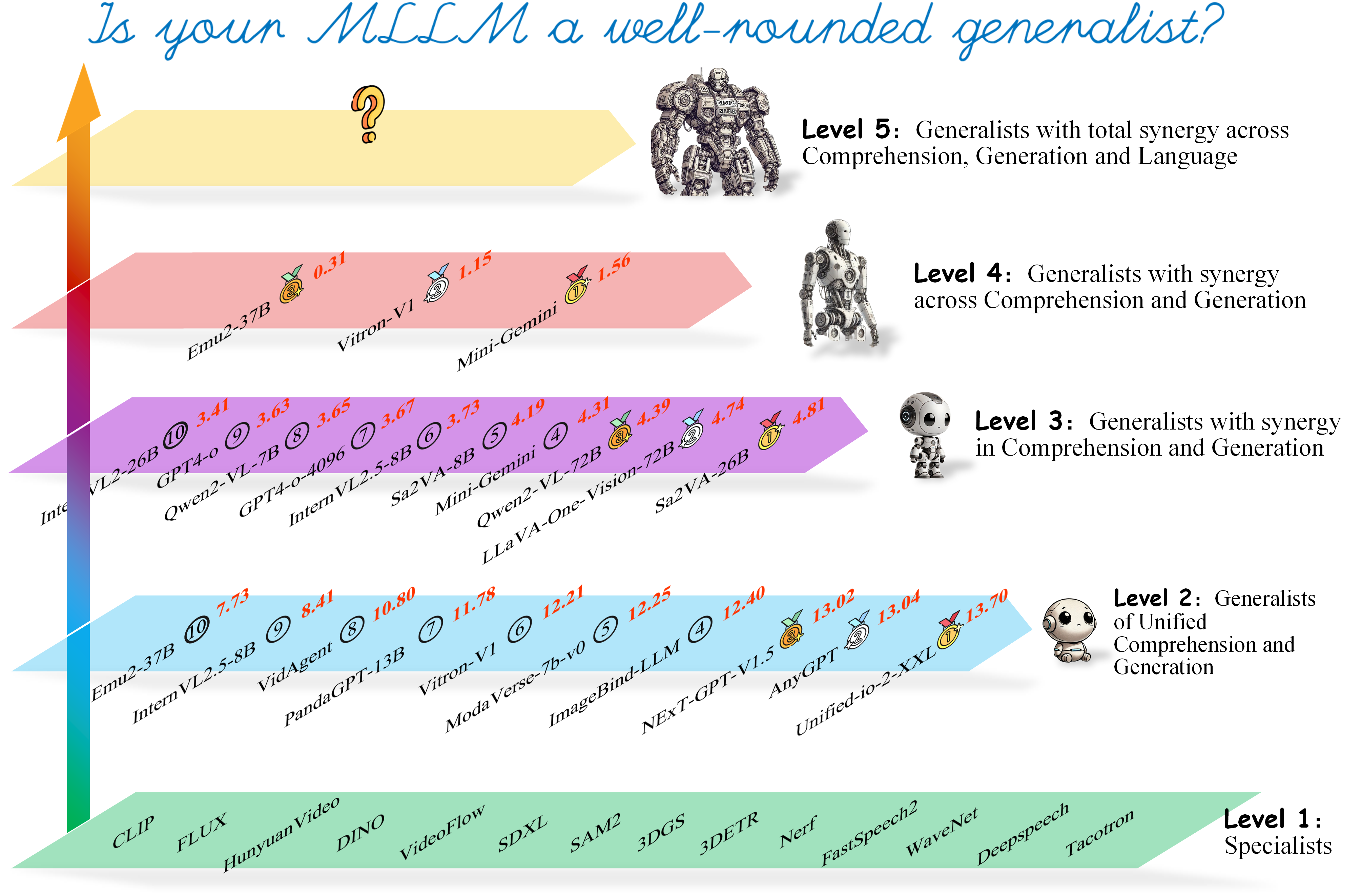
Glance at Multimodal Generalist Leaderboard 🏆 under General-Level
(Only top-performing ones shown here)
How to Participate?
-

I have my multimodal LLMs/Agents/Generalists, and I want my models shown on the leaderboards:
-
Step-1:
Chose which [leaderboard] you'd like to participate;
-
Step-2:
Download the corresponding [Close Set], and inference with your model;
-
Step-3:
Submit your evaluation results [Here].
-
-
I have my multimodal LLMs/Agents/Generalists, and I want to use the benchmark datasets for my research/papers:
Download the [Open Set], and inference on any sub sets of General-Bench with your model.
-
I have my datasets, and I want them to be included in General-Bench, and let more people to use the data:
Our General-Bench is open, and we're always welcome contribution. Please go to the [Document] page for instruction, and submit your dataset [Here]. Welcome to reach out to us for any questions.
🚀 General-Level: A 5-Level Taxonomy of Multimodal Generalists
A novel evaluation framework setting a new standard for large multimodal foundation models—charting the path toward authentic multimodal AGI.
General-Level defines 5 principal levels of model performance and generality.
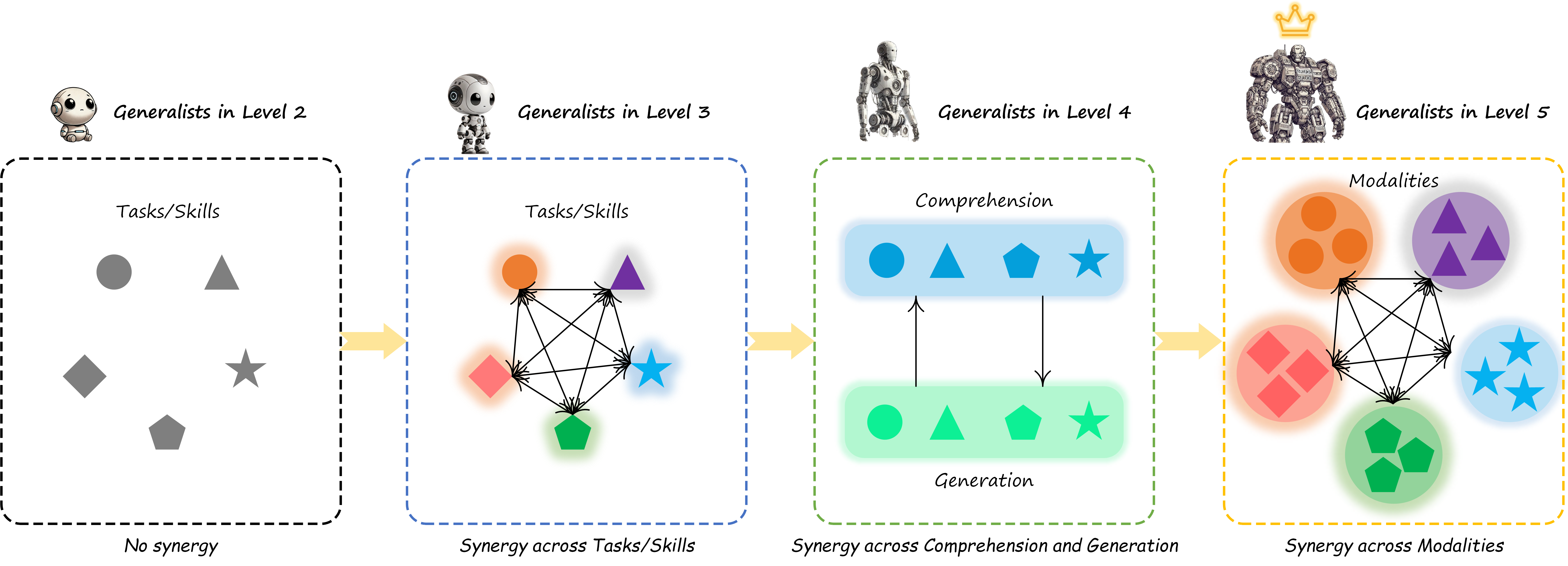
💡 Core Idea: Toward Multimodal Generalists
General-Level defines the path to stronger multimodal models—focusing on how generalists preserve synergy across multimodal comprehension and generation, as well as cross-modal interactions.
- ✔️ Encouragement: Broaden modality & task coverage — the more, the stronger
- ✔️ Core: Enable synergy and collaborative generalization across modalities and tasks, aiming for a "1+1>2" effect
- ✔️ Goal: Achieving the ideal multimodal generalist — and ultimately, multimodal AGI
On the journey to Multimodal Generalists, it’s not just about doing more—it’s about doing it better, together across modalities, functions, and tasks.
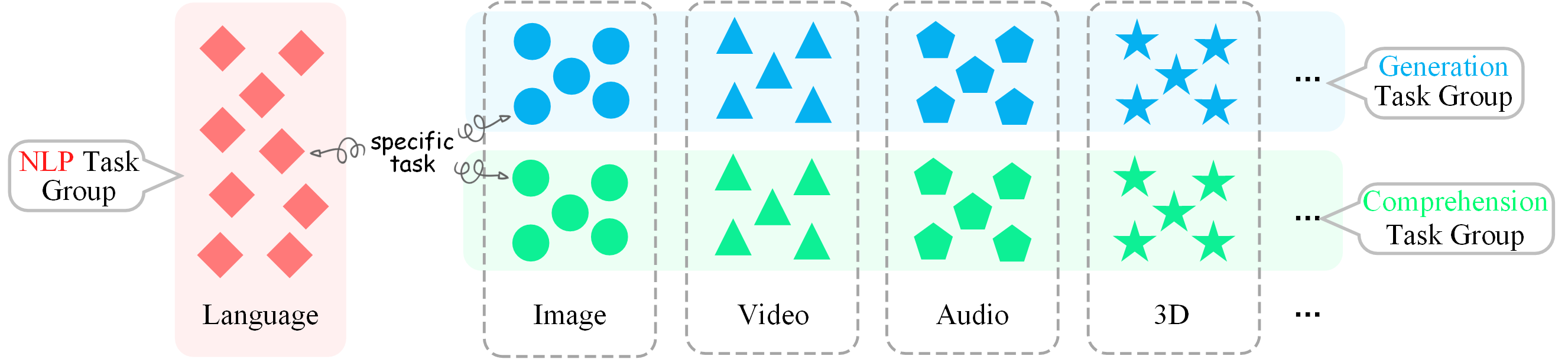
Level-1: Multimodal Specialists
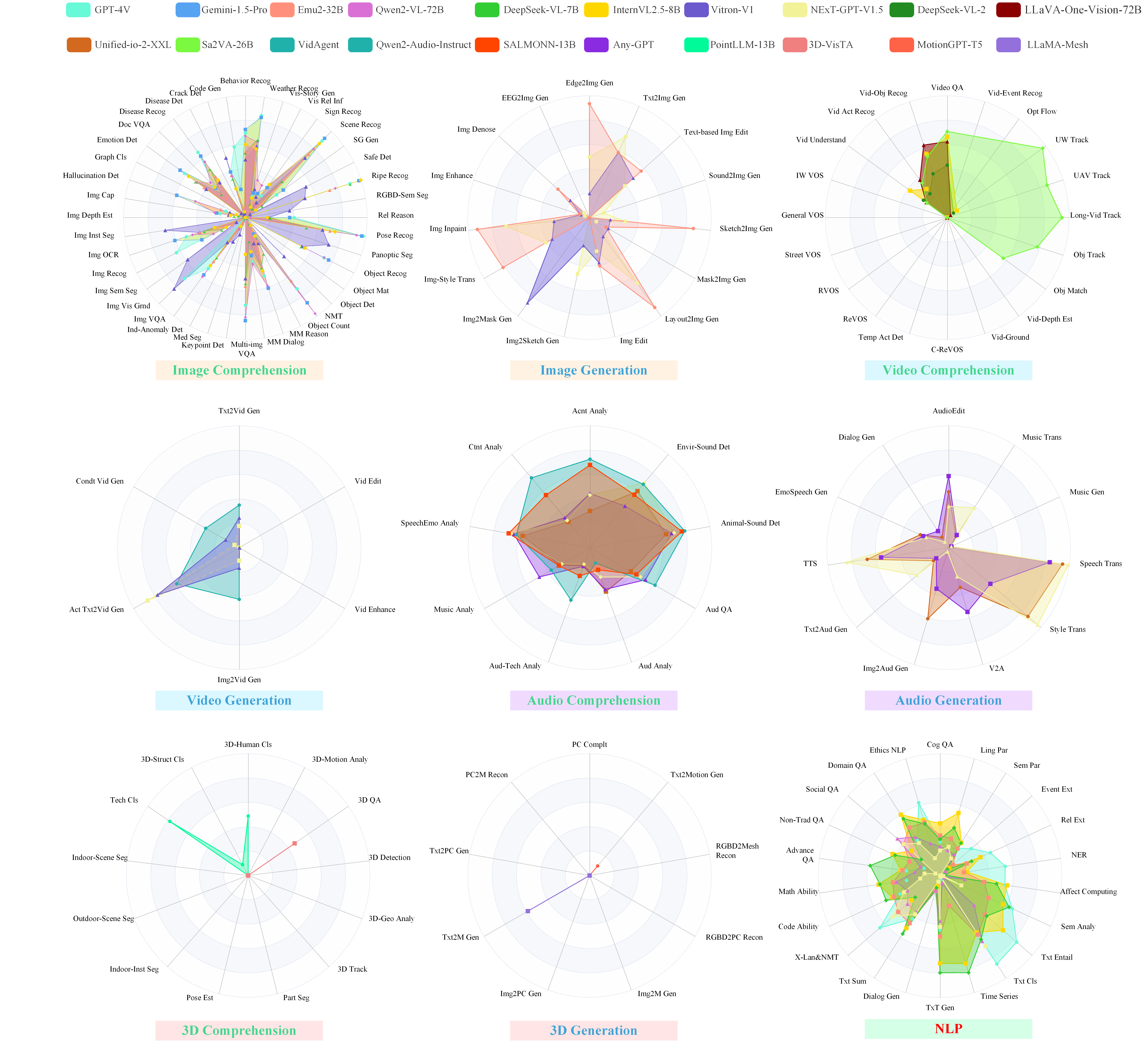
Various current models, each fine-tuned on a specific task or dataset of specific modalities, are task-specific players (i.e., SoTA specialists). This includes various learning tasks, such as linguistic/visual recognition, classification, generation, segmentation, grounding, inpainting, and more.
Scoring: For each task in the benchmark, the current SoTA specialist’s score is recorded as its SoTA performance.
Example Specialists:
- CLIP
- FLUX
- FastSpeech2
- ...

Level-2: Generalists of Unified Comprehension and/or Generation
Models are task-unified players, e.g., MLLMs, capable of supporting different modalities and tasks. Such MLLMs can integrate various models through existing encoding and decoding technologies to achieve aggregation and unification of various modalities and tasks (such as comprehension and generation tasks).
Scoring: The average score between Comprehension and Generation tasks (i.e., across all tasks) represents the score at this level. A model that can score non-zero on the data is considered capable of supporting that task. The more supported tasks and the higher the scores, the higher its overall score.
Example Generalists:
- Unified-io-2
- AnyGPT
- NExT-GPT
- ...

Level-3: Generalists with synergy in Comprehension and/or Generation
Models are task-unified players, and synergy is in Comprehension and/or Generation. MLLMs enhance several tasks’ performance beyond corresponding SoTA scores through joint learning across multiple tasks due to the synergy effect.
Scoring: For each task, assign a mask of 1 if the performance exceeds that of the state-of-the-art specialist; otherwise, assign 0. Then, calculate the average score based only on the tasks with a mask of 1. The more tasks that surpass the SoTA specialist, the higher the overall score.
Example Generalists:
- GPT-4o
- Gemini1.5
- DeepSeek-VL
- ...

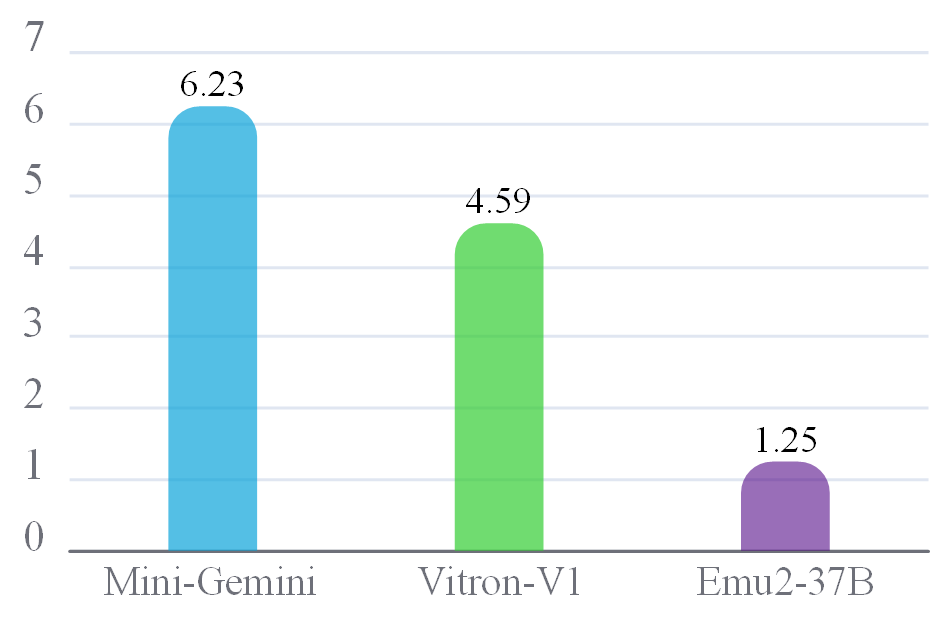
Level-4:Generalists with synergy across Comprehension and Generation
Models are task-unified players, and synergy is across Comprehension and Generation.
Scoring: Calculate the harmonic mean between Comprehension and Generation scores. The stronger synergy a model has between Comprehension and Generation tasks, the higher the score.
Example Generalists:
- Mini-Gemini
- Vitron-V1
- Emu2-37B

Level-5: Generalists with total synergy across Comprehension, Generation and Language
Models are task-unified players, preserving the synergy effect across Comprehension, Generation, and Language. In other words, the model not only achieves cross-modality synergy between Comprehension and Generation groups but also further realizes synergy with language. The Language intelligence can enhance multimodal intelligence and vice versa; understanding multimodal information can also aid in understanding language.
Scoring: Compute the model’s average score on NLP benchmarks where it outperforms SoTA NLP specialists—the more tasks it surpasses, the higher the overall score.
None found yet (Let’s wait for multimodal ChatGPT moment!)
For more details of the level scoring, please go to [Document] and [Paper]
🍕 General-Bench: A Holistic Benchmark for Multimodal Generalists
A companion massive multimodal benchmark dataset for evaluating multimodal generalists, encompasses a broader spectrum of
skills, modalities, formats, and capabilities, including over 700 tasks and 325K instances.
Rigorous Data Construction
✨ A structured 5-step process to ensure both comprehensiveness and quality.

Dual DataSet Division for Broad Utility
✨ To balance openness and leaderboard integrity, General-Bench is split into two sets: the Open Set, with fully accessible inputs and labels for public research and development; and the Close Set, which provides only inputs for fair and standardized evaluation on the leaderboard.

Diverse Leaderboard Scopes for Scalable Participation
✨ To balance evaluation cost and model readiness, we introduce a four-tier leaderboard design—from full-spectrum benchmarks for highly capable MLLMs (Scope-A) to skill-specific tracks for partial generalists (Scope-D). Our aim is to lower the entry barrier and encourages broader community involvement.
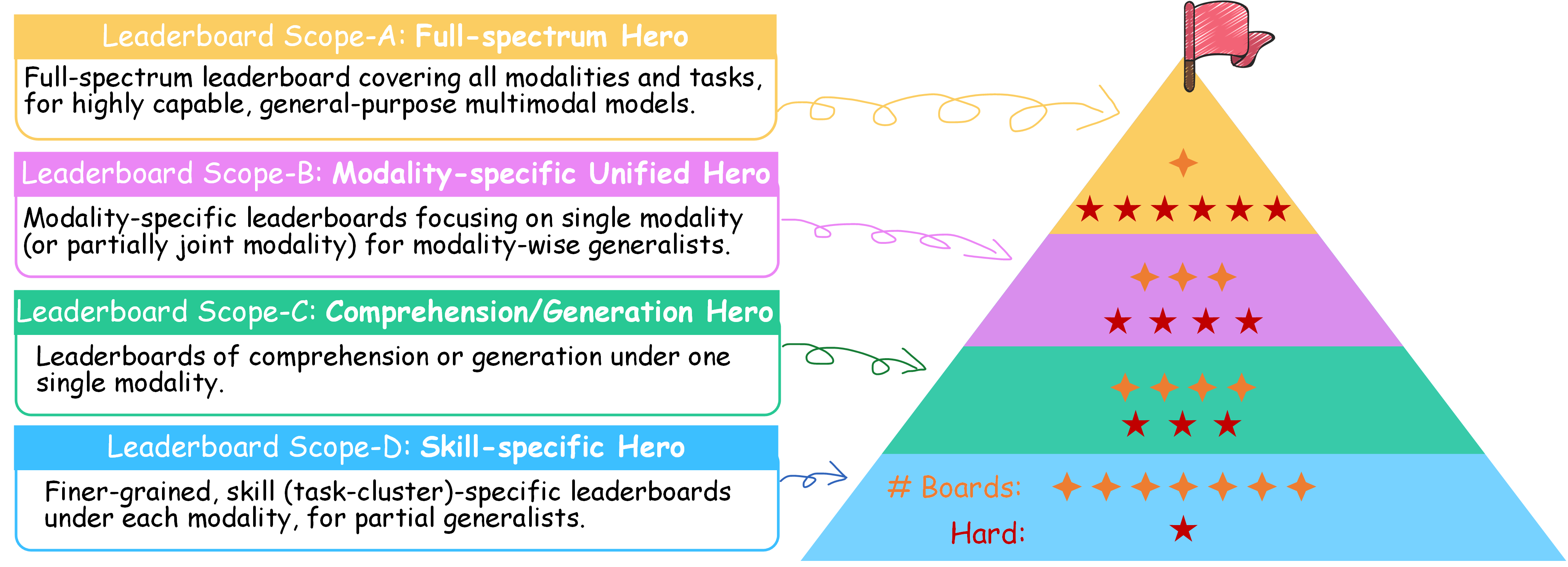
Highlight of General-Bench
✨ Comprising 145 multimodal skills, containing 702 tasks under 5 major modalities of both comprehension and generation, covering 29 domains across various totally free-form task formats (with various and raw evaluation metrics), with over 325,876 samples in total (will be further increasing).
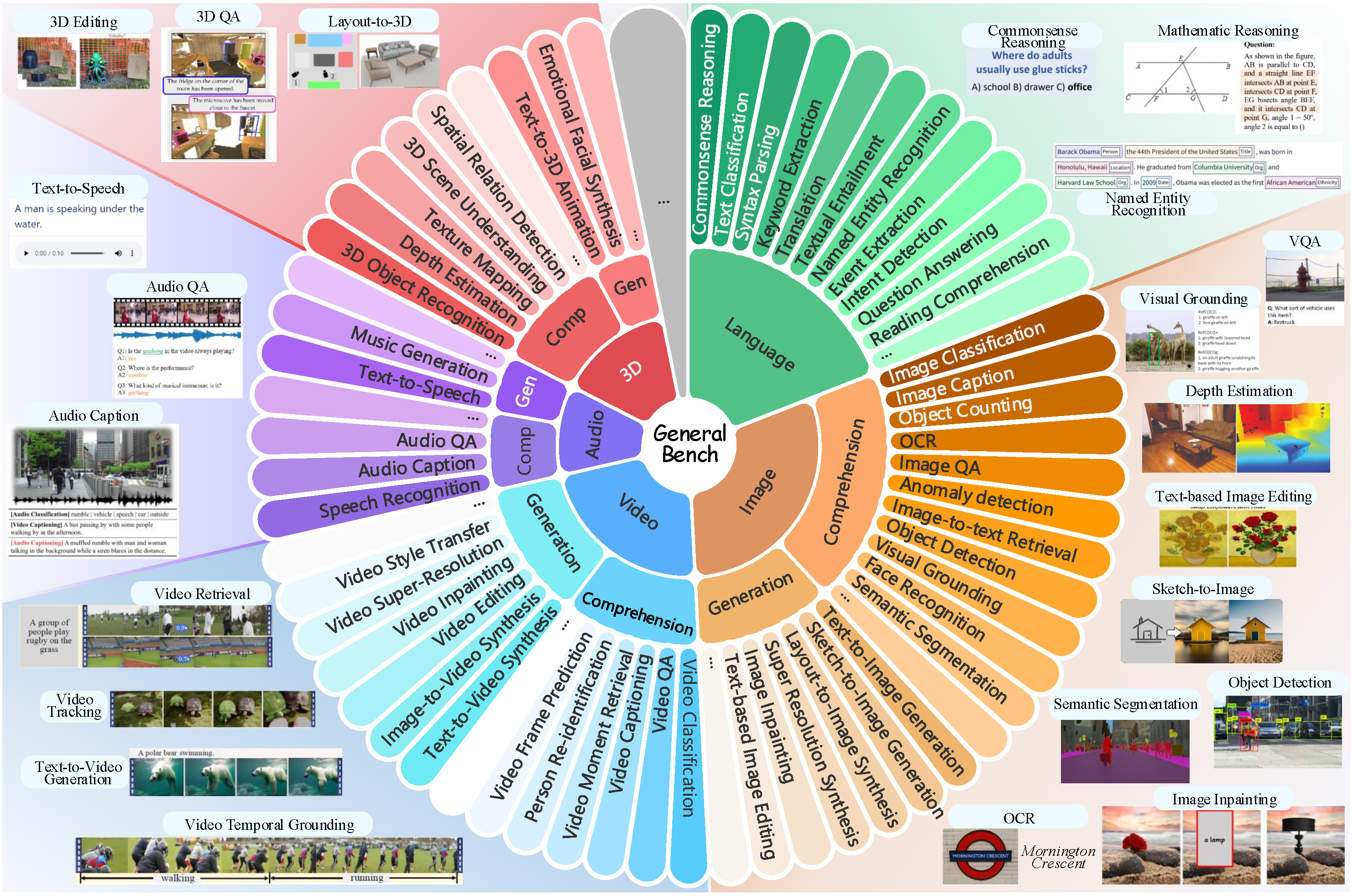
Overview
Overview of General-Bench, which covers more than 700 tasks with totally free-form task formats under comprehension and generation categories in various modalities.

Characteristics
General-Bench covers over 29 domains, evaluating more than 12 modality-persistent capabilities of generalists, as well as 145 modality-specific skills.
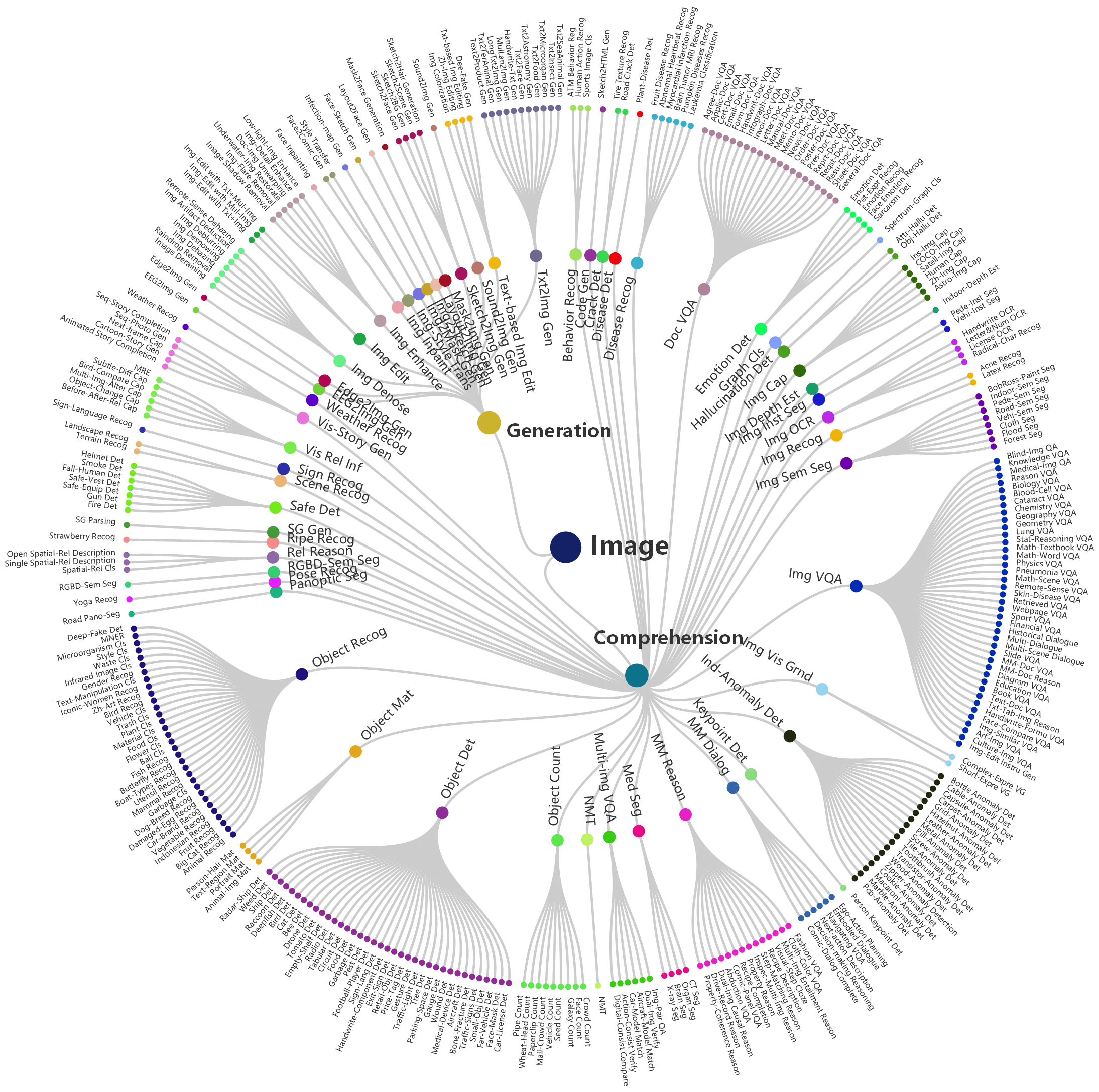
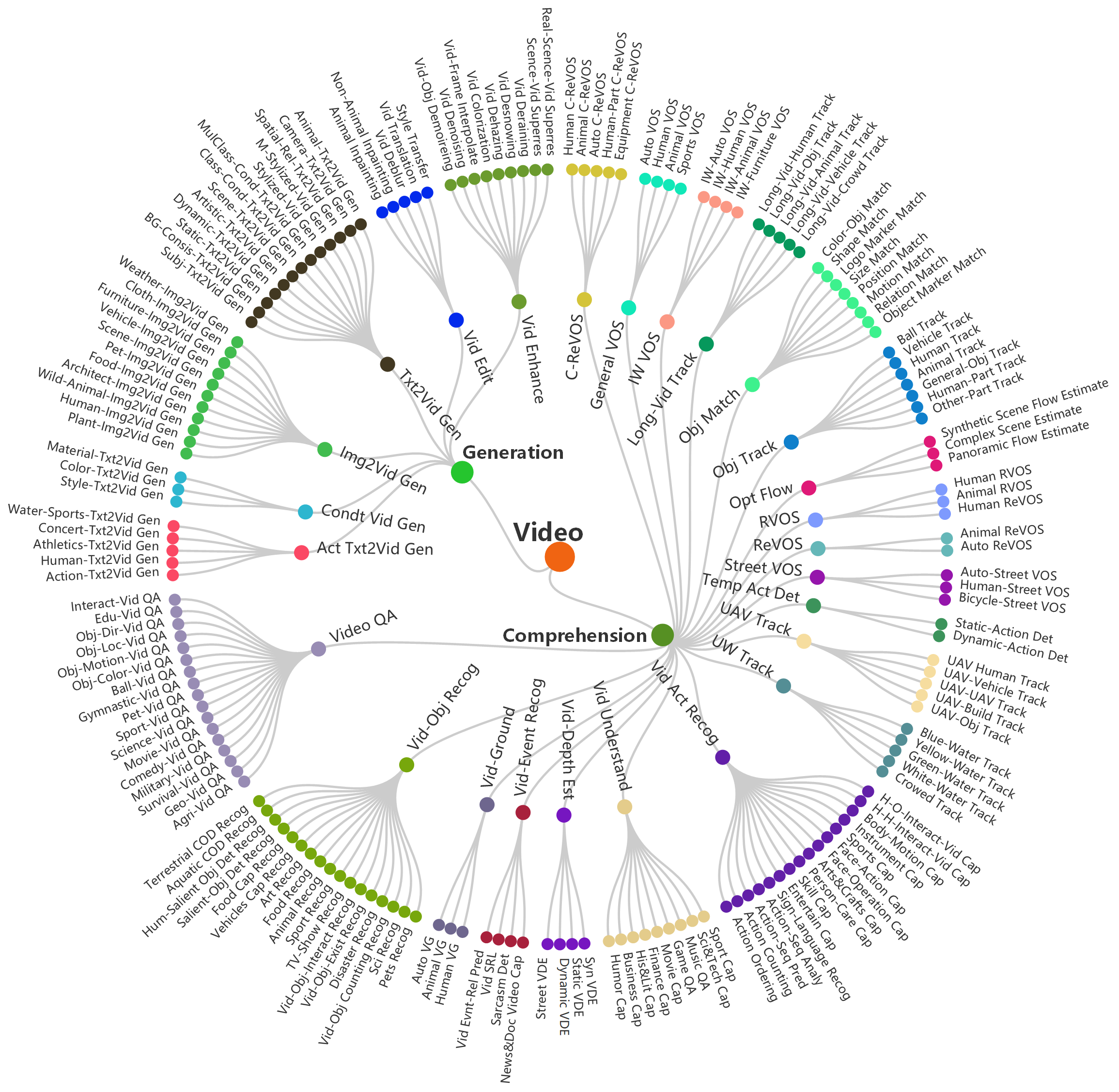
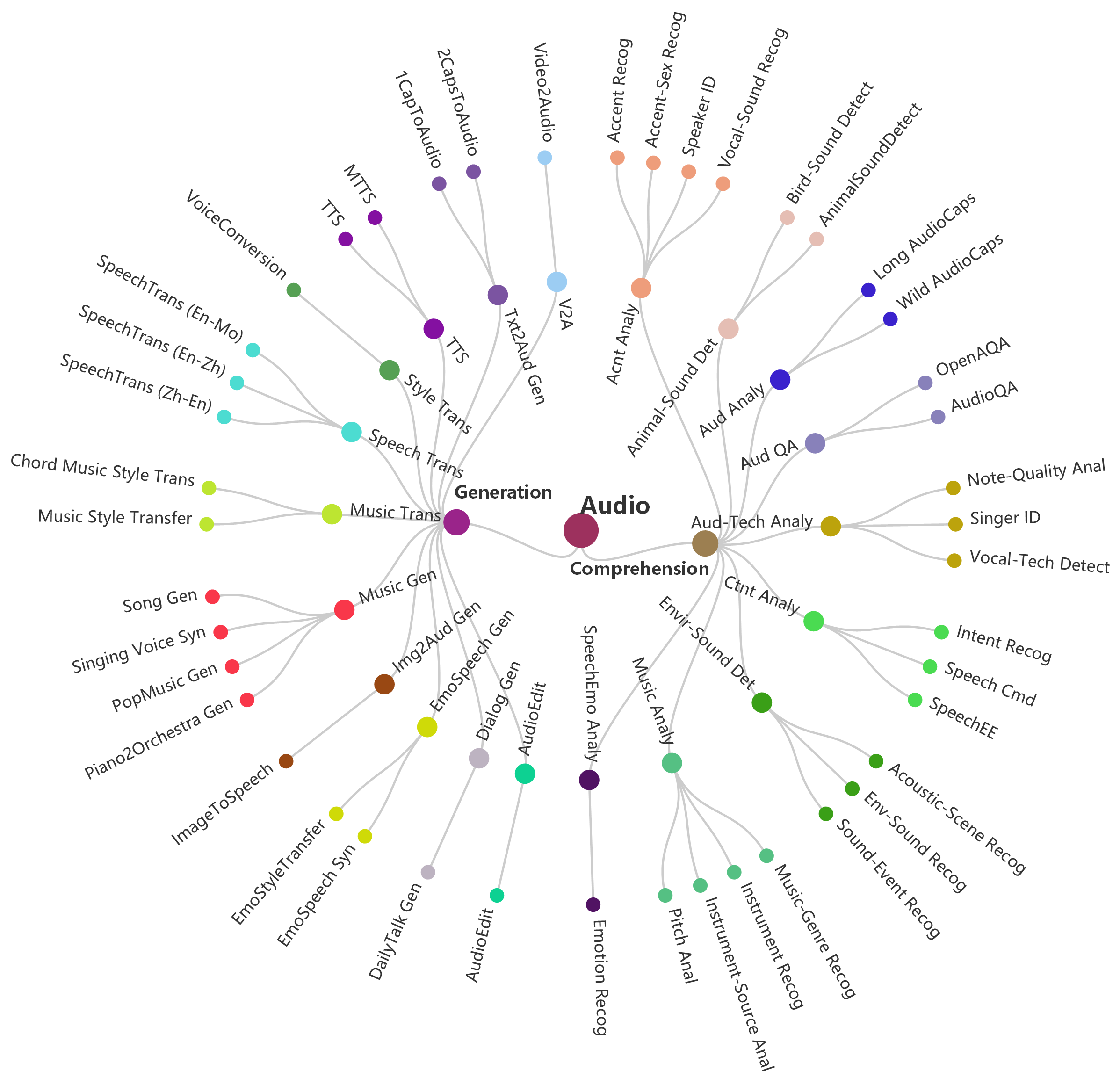
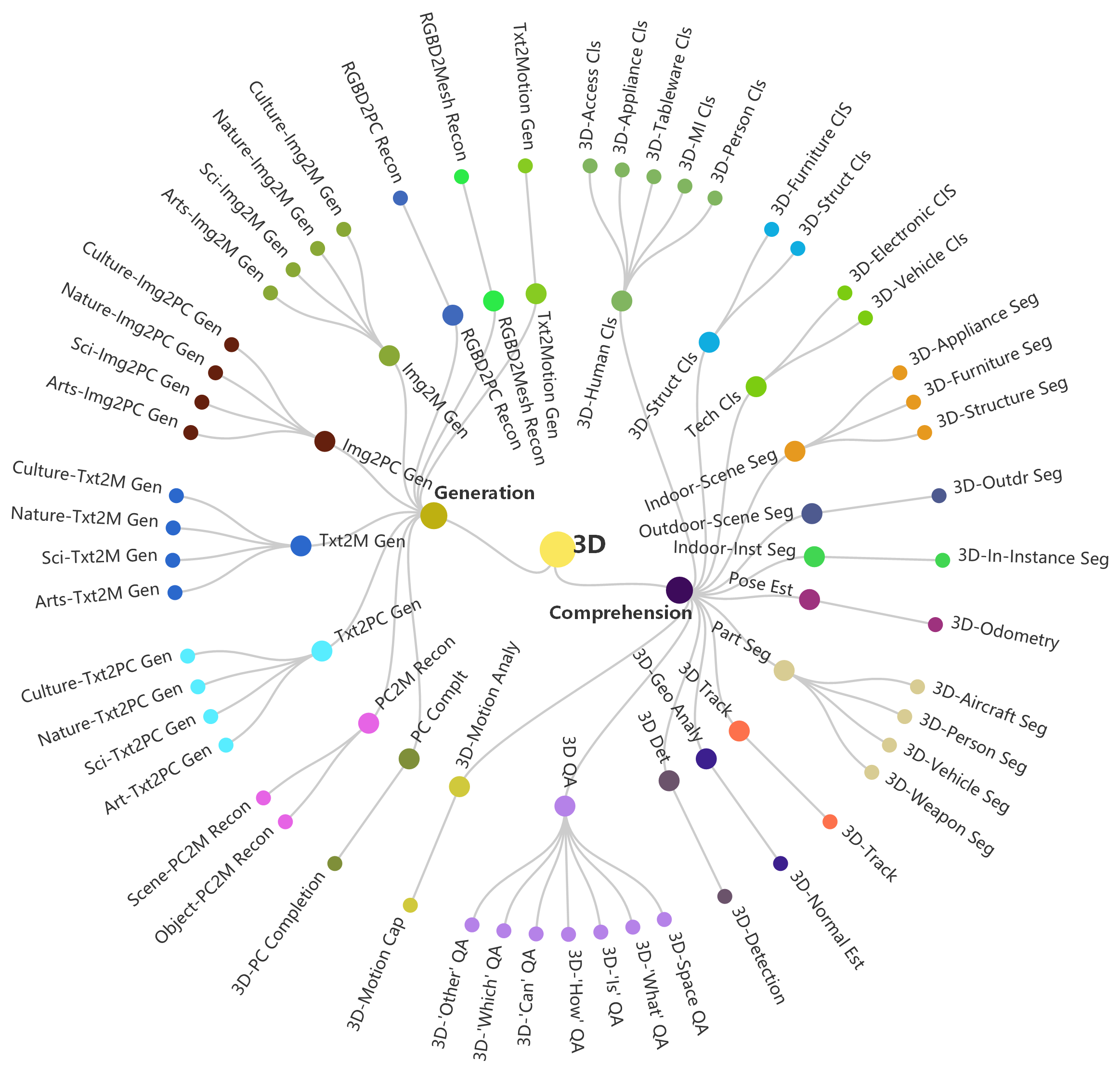

Taxonomy
Visualization of hierarchical taxonomy of General-Bench, including 5 major modalities of both comprehension and generation paradigms, skills (meta-tasks), and specific tasks.
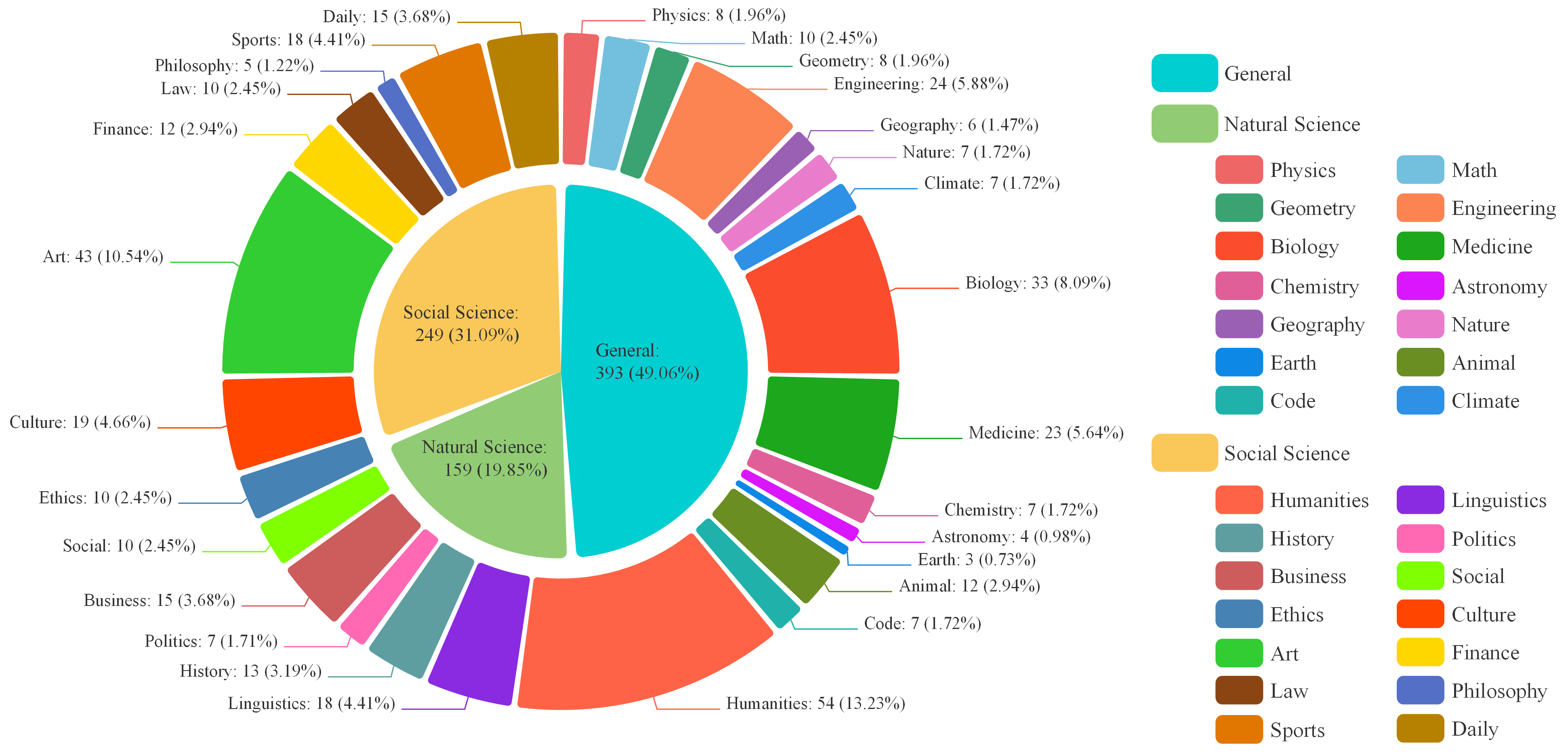
Domains and Discipline
Physics, Geometry, Biology, Medicine, Chemistry, Astronomy, Geography, Humanities, Linguistics, History, Politics, Culture, Art, and Economics.
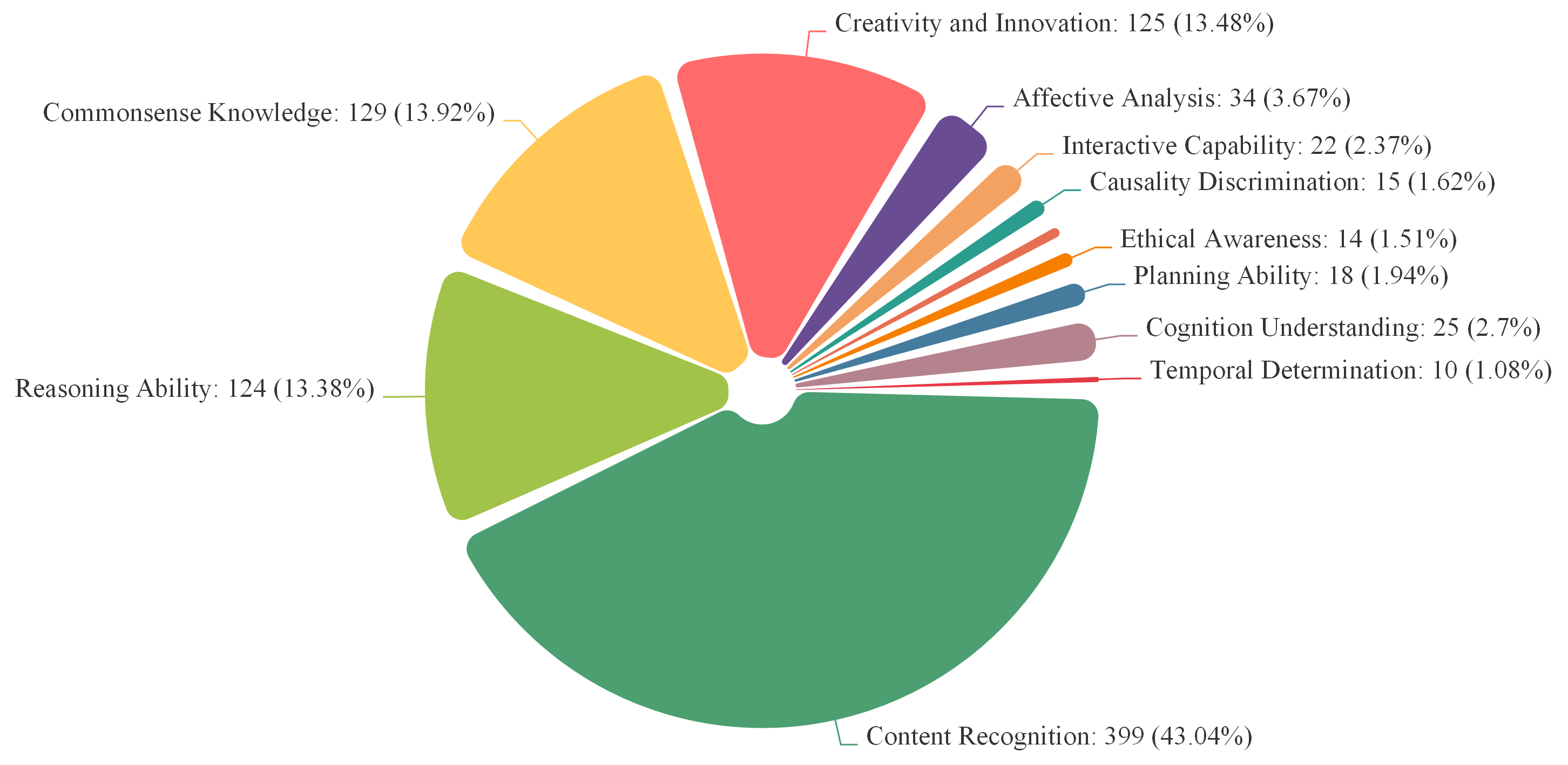
Capability
Content Recognition, Commonsense Understanding, Reasoning Ability, Causality Discrimination, Affective Analysis, Problem Solving, Creativity and Innovation ...
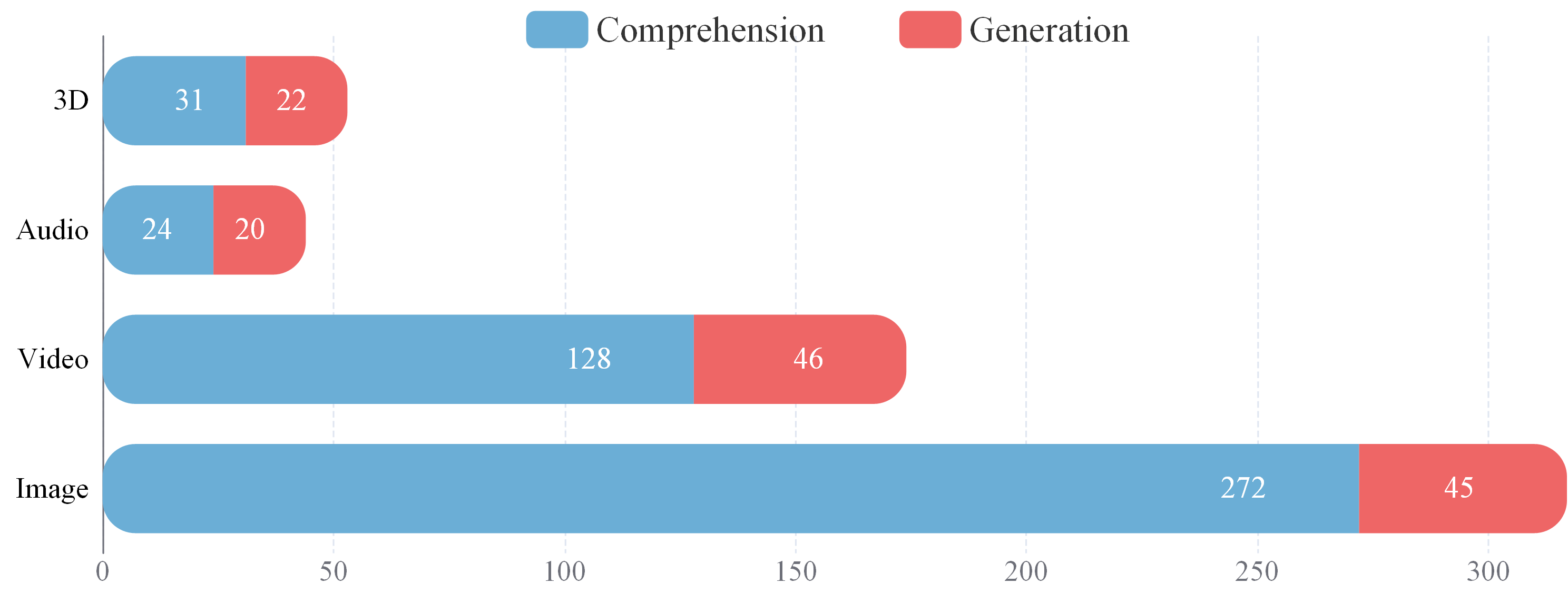
Comprehension vs. Generation.
The task distribution across the two critical paradigms, Comprehension and Generation. Currently, the majority of tasks are centered on comprehension.
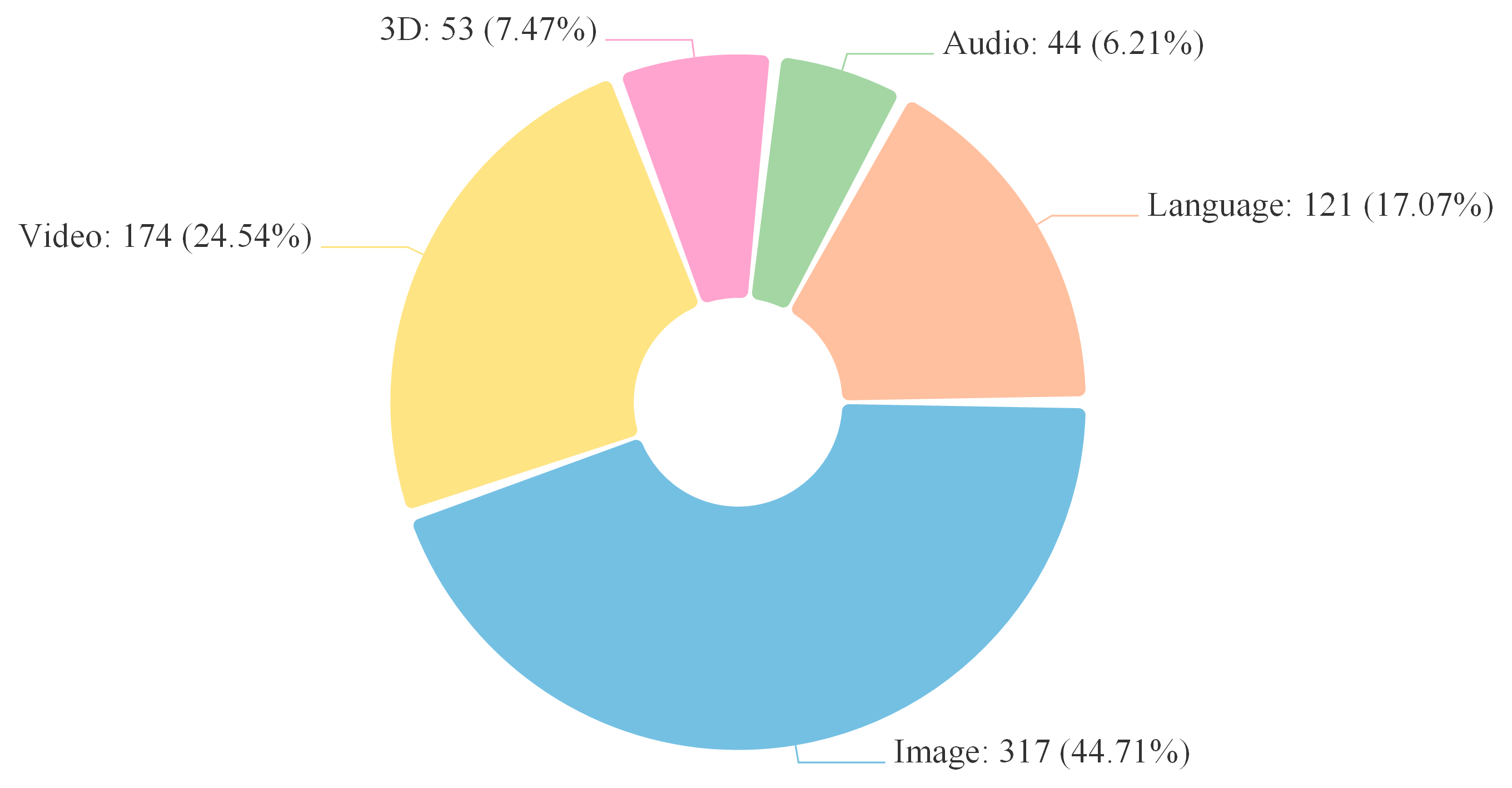
Modality
Image, Video, 3D (3D-RGB and Point-Cloud), Audio, and Language, Time Series, Depth, Infrared, Spectrogram, Radar, Code, Document, and Graph.
Experimental Analyses and Findings
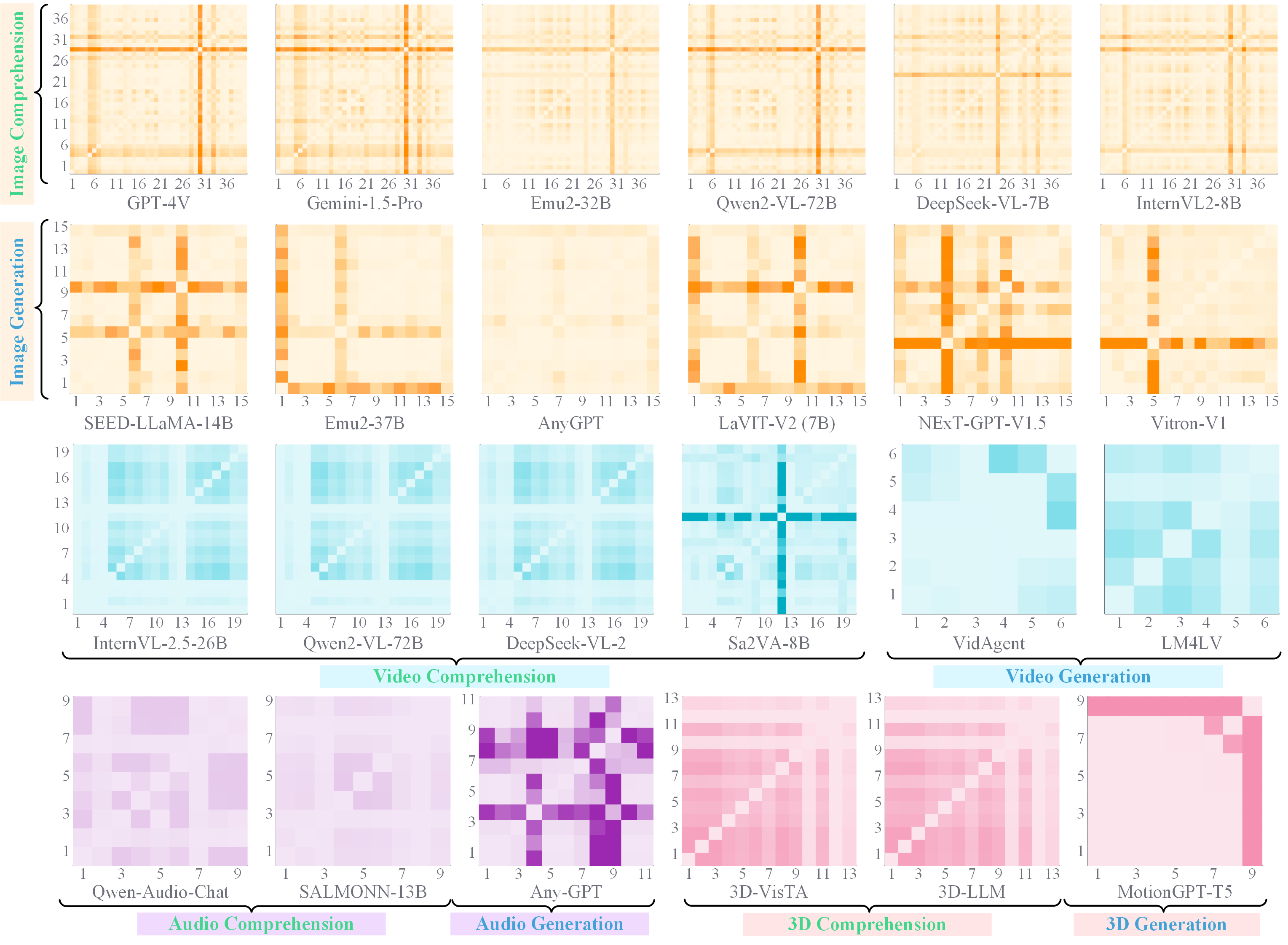
✨ Based on the General-Level framework, we conduct comprehensive experimental analysis on the General-Bench dataset using 172 specialist models and 102 generalist models, from two key perspectives: Capability Breakdown and Synergy Analysis, across three tiers: Tasks, Modalities, and Paradigms (Comprehension vs. Generation).
🧪 Capability BreakDown - Task Supporting
📢 Synergy Analysis - Synergy Across Skills
🧪 Capability BreakDown - Modality Supporting
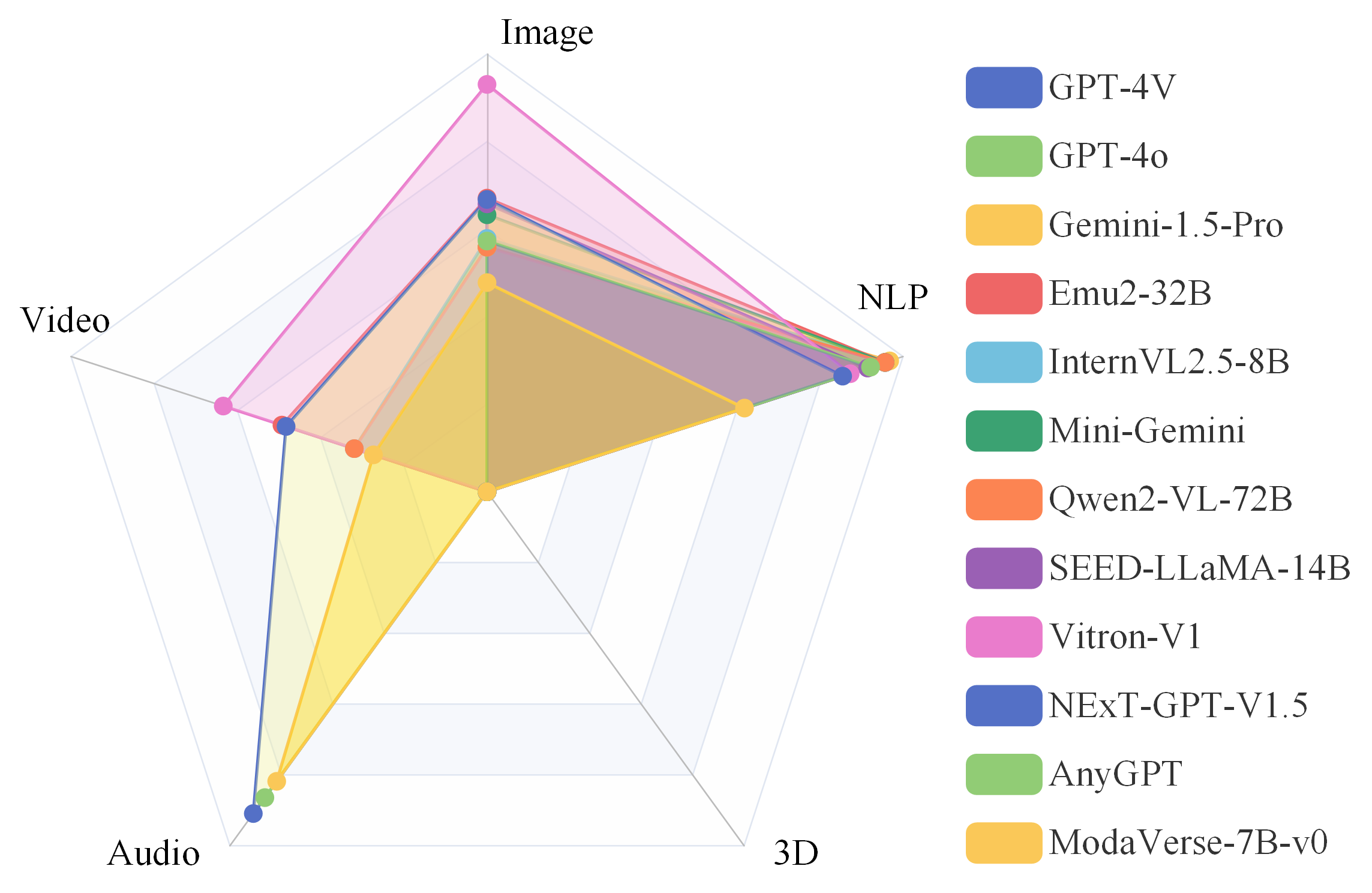
📢 Synergy Analysis - Synergy Across Modalities
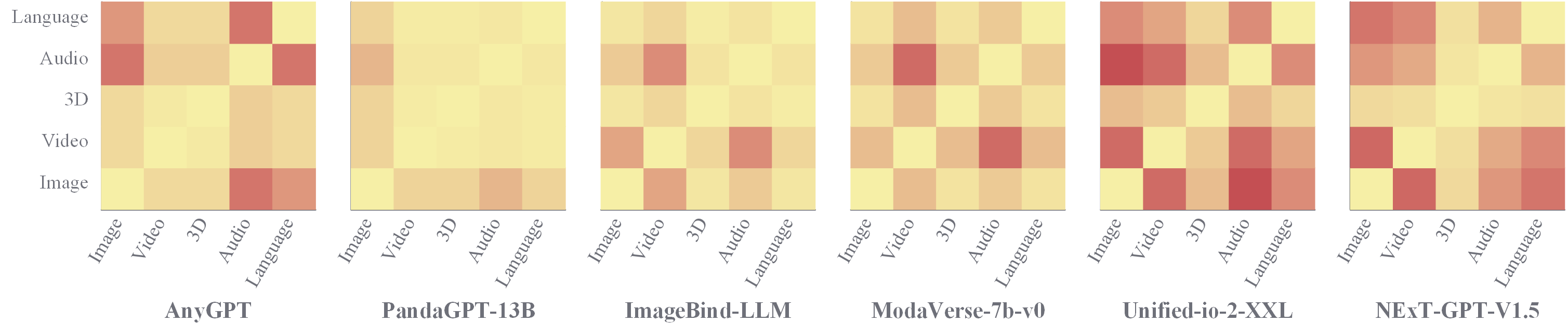
🧪 Capability BreakDown - Capabilities on Comprehension vs. Generation
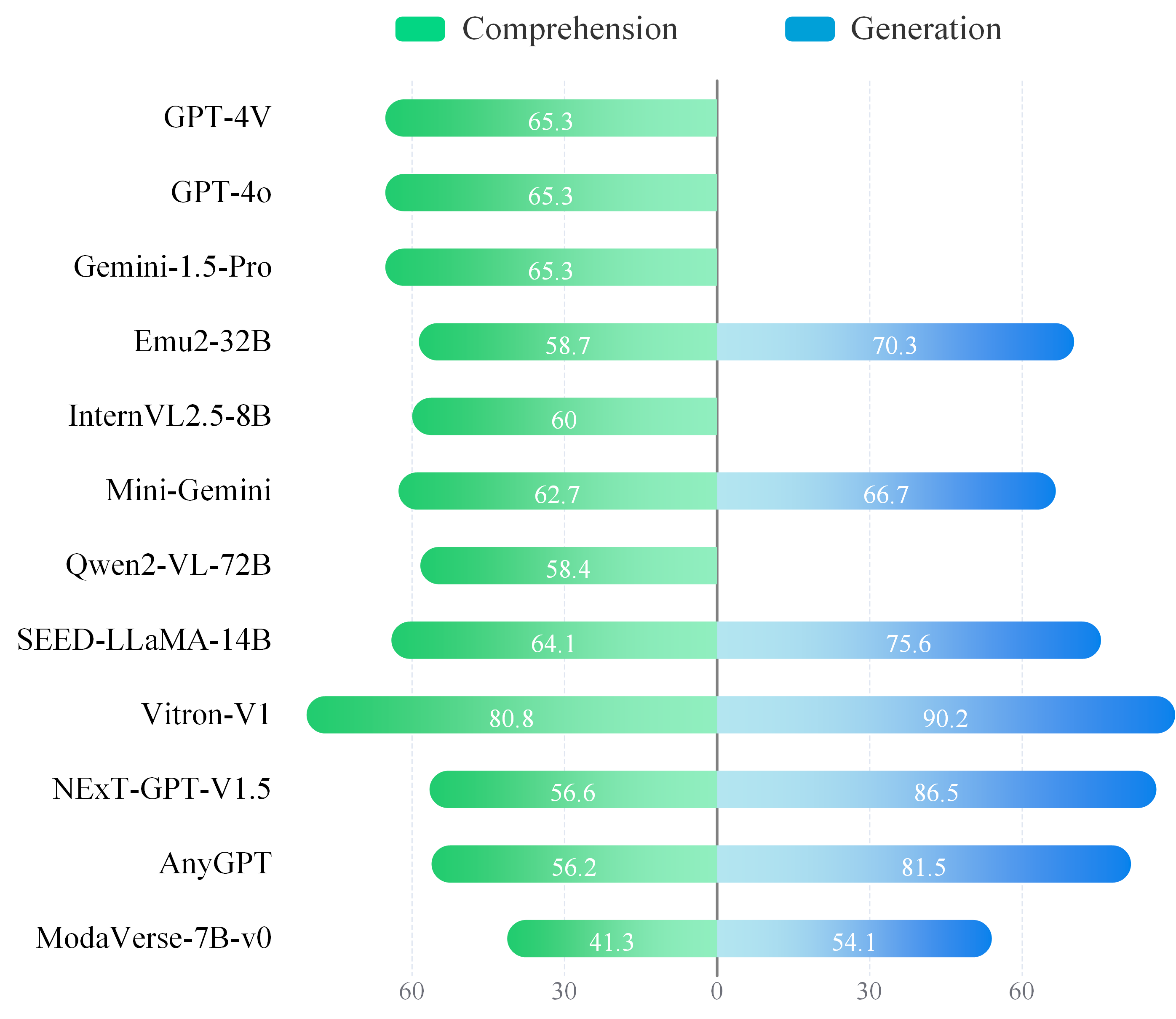
📢 Synergy Analysis - Synergy Across Comprehension and Generation
For more details of the General-Bench, please go to [Huggingface], [Leaderboard] and [Paper]
For capability diagnosis on multimodal generalists, please go to [Diagnostic] page
Team
































Join our group discussion:

Slack


Email the organizers for the project:
- All organizers: [email protected], and join our Google Group!
- Project Leader: Hao Fei ([email protected])
- Project Supervision: Hanwang Zhang ([email protected]), Shuicheng Yan ([email protected])

Email each co-leader for modality-specific queries:
- Image Leader: Yuan Zhou ([email protected]), Juncheng Li ([email protected])
- Video Leader: Xiangtai Li ([email protected])
- 3D Leader: Qingshan Xu ([email protected])
- NLP Leader: Bobo Li ([email protected])
- Audio Leader: Shengqiong Wu ([email protected])
Acknowledgement
👉 We clarify that the results of all models reported in this projects are influenced by the specific testing environment. This includes factors such as the size and content of the dataset, as well as the parameters used in the reproduced code. As we will continuously update the datasets, the evaluation results presented here may differ from those obtained in future versions. We emphasize that such differences are considered reasonable and expected deviations, and should not raise any concerns.
📌 If you find this project useful to your research, please kindly cite our paper:
@articles{fei2025pathmultimodalgeneralistgenerallevel,
title={On Path to Multimodal Generalist: General-Level and General-Bench},
author={Hao Fei and Yuan Zhou and Juncheng Li and Xiangtai Li and Qingshan Xu and Bobo Li and Shengqiong Wu and Yaoting Wang and Junbao Zhou and Jiahao Meng and Qingyu Shi and Zhiyuan Zhou and Liangtao Shi and Minghe Gao and Daoan Zhang and Zhiqi Ge and Weiming Wu and Siliang Tang and Kaihang Pan and Yaobo Ye and Haobo Yuan and Tao Zhang and Tianjie Ju and Zixiang Meng and Shilin Xu and Liyu Jia and Wentao Hu and Meng Luo and Jiebo Luo and Tat-Seng Chua and Shuicheng Yan and Hanwang Zhang},
eprint={2505.04620},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.04620},
}
🙏 We sincerely thank the following individuals for their contributions to this project, who however are not included into the author list for certain reasons.