Leaderboards of General-Level
General-Level evaluates generalists based on the levels and strengths of the synergy they preserve. Specifically, we define three scopes of synergy, ranked from low to high: no synergy, task-level synergy (‘task-task’), paradigm-level synergy (‘comprehension-generation’), and cross-modal total synergy (‘modality-modality’), as illustrated here:
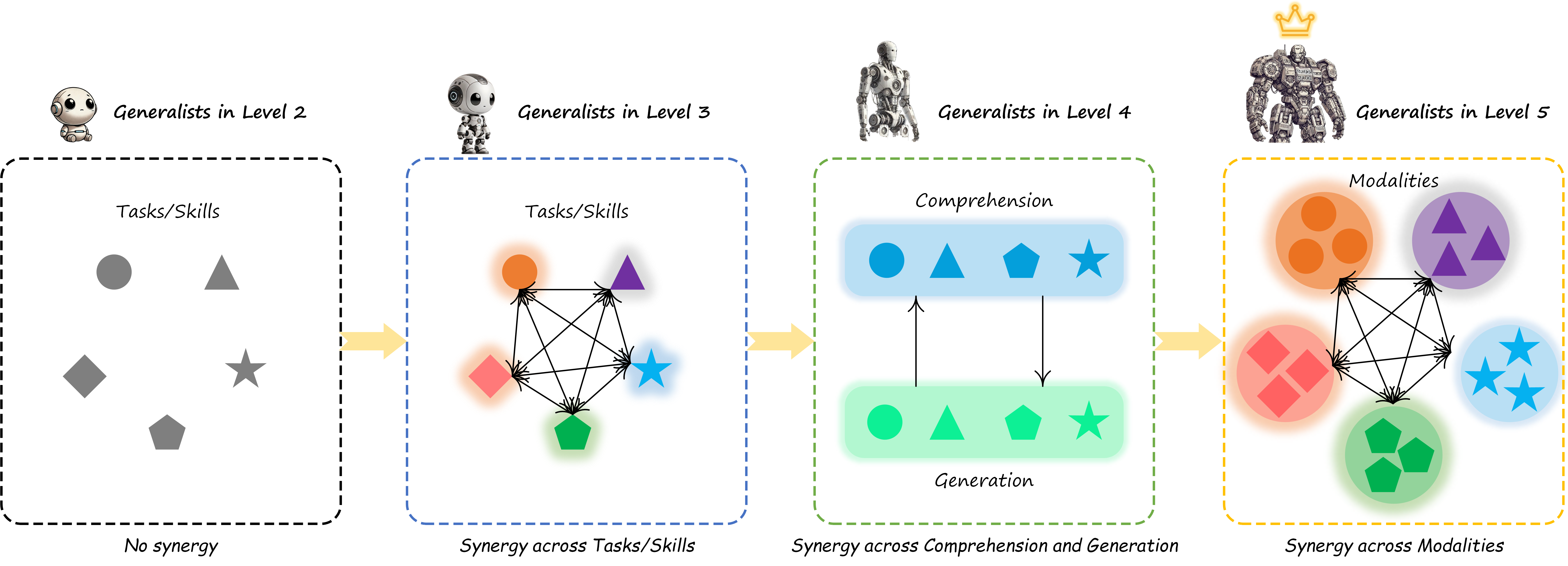
Achieving these levels of synergy becomes progressively more challenging, corresponding to higher degrees of general intelligence. Assume we have a benchmark of various modalities and tasks, where we can categorize tasks under these modalities into the Comprehension group and the Generation group, as well as the language (i.e., NLP) group, as illustrated here:
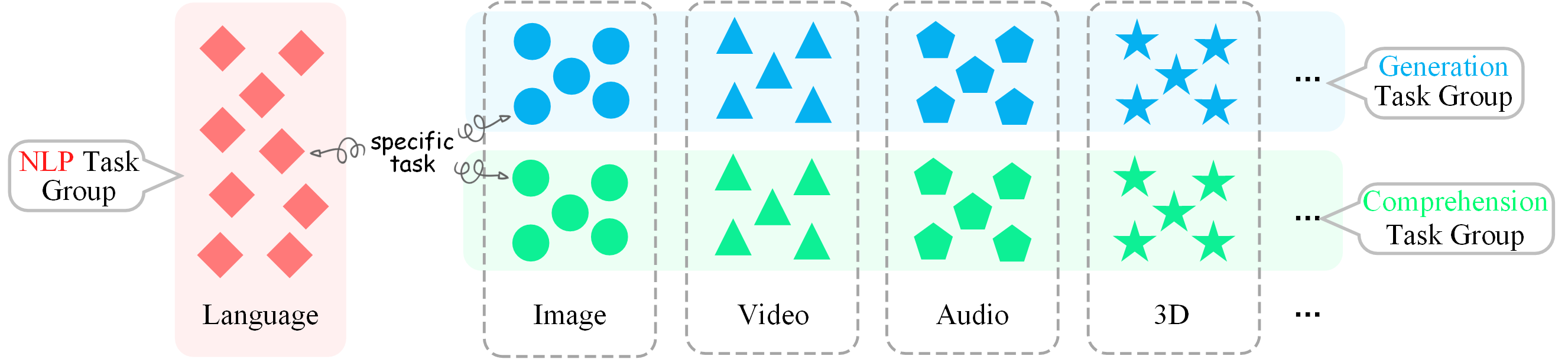
Let’s denote the number of datasets or tasks within the Comprehension task group by \( M \); the number within the Generation task group by \( N \); and the number of NLP tasks by \( T \).
Now, we demonstrate the specific definition and calculation of each level:
| Level | Definition | Scoring | Example |
|---|---|---|---|
| Level-1: Specialist |
Various current models, each fine-tuned on a specific task or dataset of specific modalities, are task-specific players (i.e., SoTA specialists). This includes various learning tasks, such as linguistic/visual recognition, classification, generation, segmentation, grounding, inpainting, and more. | For each task in the benchmark (\(i\)-th task), the current SoTA specialist’s score is recorded as: $$\sigma_i^{sota}$$ | CLIP, FLUX, FastSpeech2, SAM, Dino, DALLe ... |
| ↓ Upgrading Conditions: Supporting as many tasks and functionalities as possible. | |||
|
Level-2 (No Synergy): Generalist of Unified Comprehension and Generation 
|
Models are task-unified players, e.g., MLLMs, capable of supporting different modalities and tasks. Such MLLMs can integrate various models through existing encoding and decoding technologies to achieve aggregation and unification of various modalities and tasks (such as comprehension and generation tasks). | The average score between Comprehension and Generation tasks (i.e., across all tasks) represents the score at this level. A model that can score non-zero on the data is considered capable of supporting that task. The more supported tasks and the higher the scores, the higher its overall score: $$ S_2 = \frac{1}{2} \left( \frac{1}{M} \sum^{M}_{i=1} \sigma_{i}^{C} + \frac{1}{N} \sum^{N}_{j=1} \sigma_{i}^{G} \right) $$ | Unified-io-2, AnyGPT, NExT-GPT, SEED-LLaMA, GPT-4V ... |
| ↓ Upgrading Conditions: Generalists achieving as stronger synergy and cross as many tasks as possible. | |||
| Level-3 (Task-level Synergy): Generalist with Synergy in Comprehension and/or Generation 
|
Models are task-unified players, and synergy is in Comprehension and/or Generation. MLLMs enhance several tasks' performance beyond corresponding SoTA scores through joint learning across multiple tasks due to the synergy effect. | Assign a mask weight of 0 or 1 to each task; mask=1 only if the corresponding score ( \( \sigma_i^{C} \) or \( \sigma_i^{G}\) ) exceeds the SoTA specialist's score, otherwise mask=0. Then, calculate the average score between \(S_C\) and \(S_G\). The more tasks to surpass the SoTA specialist, the higher the \( S_3\) : $$ S_3 = \frac{1}{2} \left( S_G + S_C \right) , \,\;\;\; \text{where} \\ S_C = \frac{1}{M} \sum_{i=1}^M \begin{cases} \sigma^{C}_i,\,\;\;\; \text{if} \sigma_i^{C} \geq \sigma^{C}_{sota} \\\\ 0 \,,\,\;\;\; \text{otherwise} \end{cases} \\ S_G = \frac{1}{N} \sum_{j=1}^N \begin{cases} \sigma^{G}_j, \,\;\;\; \text{if} \sigma^{G}_j \geq \sigma^{G}_{sota} \\\\ 0 \,,\,\;\;\; \text{otherwise} \end{cases} $$ | GPT-4o, Gemini-1.5, Claude-3.5, DeepSeek-VL, LLaVA-One-Vision, Qwen2-VL, InternVL2.5, Phi-3.5-Vision, |
| ↓ Upgrading Conditions: Generalists in unified comprehension and generation capability with synergy in between. | |||
| Level-4 (Paradigm-level Synergy): Generalist with Synergy across Comprehension and Generation 
|
Models are task-unified players, and synergy is across Comprehension and Generation. | Calculate the harmonic mean between Comprehension and Generation scores. The stronger synergy a model has between Comprehension and Generation tasks, the higher the score: $$ S_4 = \frac{2 S_C S_G}{S_C + S_G} $$ | Mini-Gemini, Vitron-V1, Emu2-37B, ... |
| ↓ Upgrading Conditions: Generalists achieving cross-modal synergy with abductive reasoning. | |||
| Level-5 (Cross-modal Total Synergy): Generalist with Total Synergy across Comprehension, Generation, and NLP 
|
Models are task-unified players, preserving the synergy effect across Comprehension, Generation, and NLP. In other words, the model not only achieves cross-modality synergy between Comprehension and Generation groups but also further realizes synergy with language. The Language intelligence can enhance multimodal intelligence and vice versa; understanding multimodal information can also aid in understanding language. | Calculate the model's average score exceeding SoTA NLP specialists on NLP benchmark data; normalize it to a [0,1] weight, and multiply it by the score from level-4 as the level-5 score: $$ S_{5} = S_4 \times w_L, \,\;\;\; \text{where} \\ w_L = \frac{S_L}{S_{total}}, \\ S_L = \frac{1}{T} \sum_{k=1}^{T} \begin{cases} \sigma_k, \; \sigma_k \geq \sigma_k^{sota} \\\\ 0 \,,\,\;\;\; \text{otherwise} \end{cases} $$ | None found yet (Let's wait for multimodal ChatGPT moment!) |
⚠️ Scoring Relaxation
A central aspect of our General-Level framework lies in how synergy effects are computed. According to the standard understanding of the synergy concept, e.g., the performance of a generalist model on joint modeling of tasks A and B (e.g., \( P_\theta(y|A,B)\) ) should exceed its performance when modeling task A alone (e.g., \( P_\theta(y|A)\) ) or task B alone (e.g., \( P_\theta(y|B)\) ). However, adopting this approach poses a significant challenge that hinders the measurement of synergy: there is no feasible way to establish two independent distributions, \( P_\theta(y|A)\) and \( P_\theta(y|B)\) , and a joint distribution \( P_\theta(y|A,B)\) . This limitation arises because a given generalist model has already undergone extensive pre-training and fine-tuning, where tasks A and B have likely been jointly modeled. It is impractical to retrain such a generalist to isolate the learning and modeling of tasks A or B independently in order to derive these distributions. Otherwise, such an approach would result in excessive redundant computation and inference on the benchmark data.
To simplify and relax the evaluation of synergy, we introduce a key assumption in the scoring algorithm:
By making this assumption, we avoid the need for direct pairwise measurements between `task-task', `comprehension-generation', or `modality-modality', which would otherwise require complex and computationally intensive algorithms.
Four-scoped Leaderboard
To balance evaluation cost and model readiness, we introduce a four-tier leaderboard design—from full-spectrum benchmarks for highly capable MLLMs (Scope-A) to skill-specific tracks for partial generalists (Scope-D). Our aim is to lower the entry barrier and encourages broader community involvement.
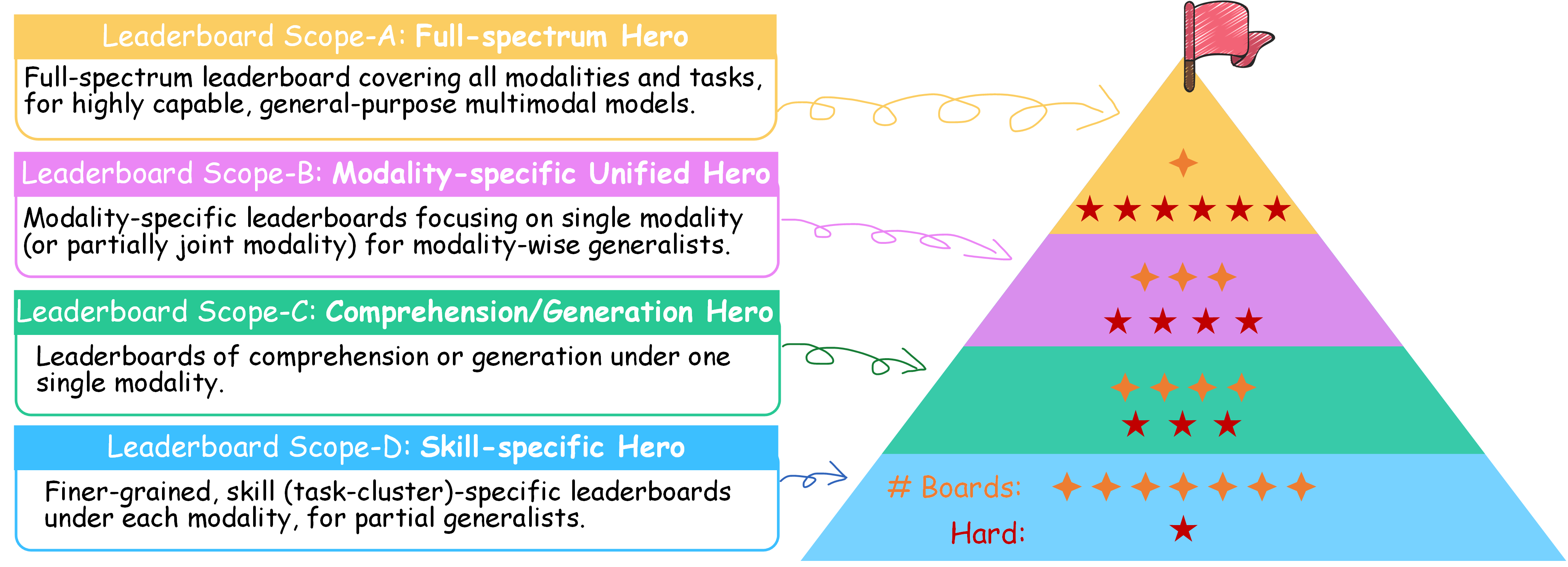

Go ahead and select a leaderboard that best fits your model’s strengths! 😎
👑 Scope-A: Full-spectrum Hero

Full-spectrum leaderboard covering all modalities and tasks under General-Level, for highly capable, general-purpose multimodal models.
📊 Difficulty: ⭐⭐⭐⭐⭐⭐
🍕 Number of leaderboards: ⭐
🔍 Details:
- ✔️ Covers all General-Level tasks and modalities.
- ✔️ Most challenging track; requires high model capacity and resource commitment.
🎉 Highlights:
- ✔️ Evaluates holistic generalization and cross-modal synergy.
- ✔️ Suitable for near-AGI or foundation-level multimodal generalists.
💎 Scope-B: Modality-specific Unified Hero

Modality-specific leaderboards focusing on single modality or partially joint modality (e.g., image, video, audio, 3D) for modality-wise generalists.
📊 Difficulty: ⭐⭐⭐⭐
🍕 Number of leaderboards: ⭐⭐⭐
🔍 Details:
- ✔️ 7 separate leaderboards (4 single modality + 3 combined modality).
- ✔️ Focuses on mastering diverse tasks within a single modality.
🎉 Highlights:
- ✔️ Measures within-modality generalization.
- ✔️ Suited for intermediate-level models with cross-task transferability.
💪 Scope-C: Comprehension/Generation Hero

Leaderboards categorized by comprehension vs. generation tasks within each modality. Lower entry barrier for early-stage or lightweight models.
📊 Difficulty: ⭐⭐⭐
🍕 Number of leaderboards: ⭐⭐⭐⭐
🔍 Details:
- ✔️ 8 leaderboards: 2 × 4 for multimodal comprehension/generation under different modalities.
- ✔️ Supports entry-level model evaluation or teams with limited resources.
🎉 Highlights:
- ✔️ Assesses task-type specialization: understanding or generation.
- ✔️ Reflects generalization across task types.
🛠️ Scope-D: Skill-specific Hero
Fine-grained leaderboards focused on specific task clusters (e.g., VQA, Captioning, Speech Recognition), ideal for partial generalists.
📊 Difficulty: ⭐
🍕 Number of leaderboards: ⭐⭐⭐⭐⭐⭐⭐
🔍 Details:
- ✔️ Large number of sub-leaderboards, each scoped to a skill set.
- ✔️ Easiest to participate; lowest cost.
🎉 Highlights:
- ✔️ Evaluates fine-grained skill performance.
- ✔️ Helps identify model strengths and specialization areas.
- ✔️ Encourages progressive development toward broader leaderboard participation.