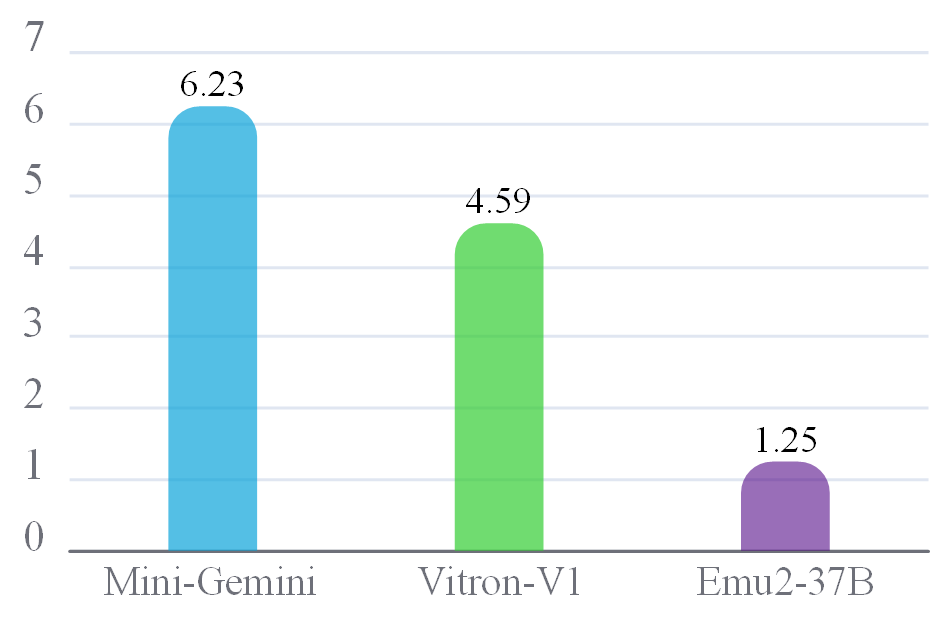
Model Diagnostics

In this page, we present a comprehensive diagnostic analysis of multimodal generalist models that are included in our General-Bench 🧠 leaderboard. Built upon an exceptionally large-scale, multi-dimensional 📊 evaluation benchmark, General-Bench enables broad and in-depth assessment across diverse modalities, tasks, and paradigms 🔄.
While leaderboard rankings 🏅 offer a high-level view of overall performance, they often mask the nuanced strengths and weaknesses exhibited by each model across different dimensions. To bridge this gap, our Model Diagnostics aims to unpack these subtleties—identifying where each model excels 💪 and where it struggles ⚠️ across modalities, capabilities, and task types.
We believe such fine-grained diagnostics are essential for guiding the future development of stronger and more robust multimodal models 🚀. We believe this effort plays a critical role in advancing the field toward truly universal multimodal generalists—and ultimately, Artificial General Intelligence (AGI) 🤖.
Experimental Analyses and Findings
✨ Based on the General-Level framework, we conduct comprehensive experimental analysis on the General-Bench dataset using 172 specialist models and 102 generalist models, from two key perspectives: Capability Breakdown and Synergy Analysis, across three tiers: Tasks, Modalities, and Paradigms (Comprehension vs. Generation).
🧪 Capability BreakDown - Task Supporting
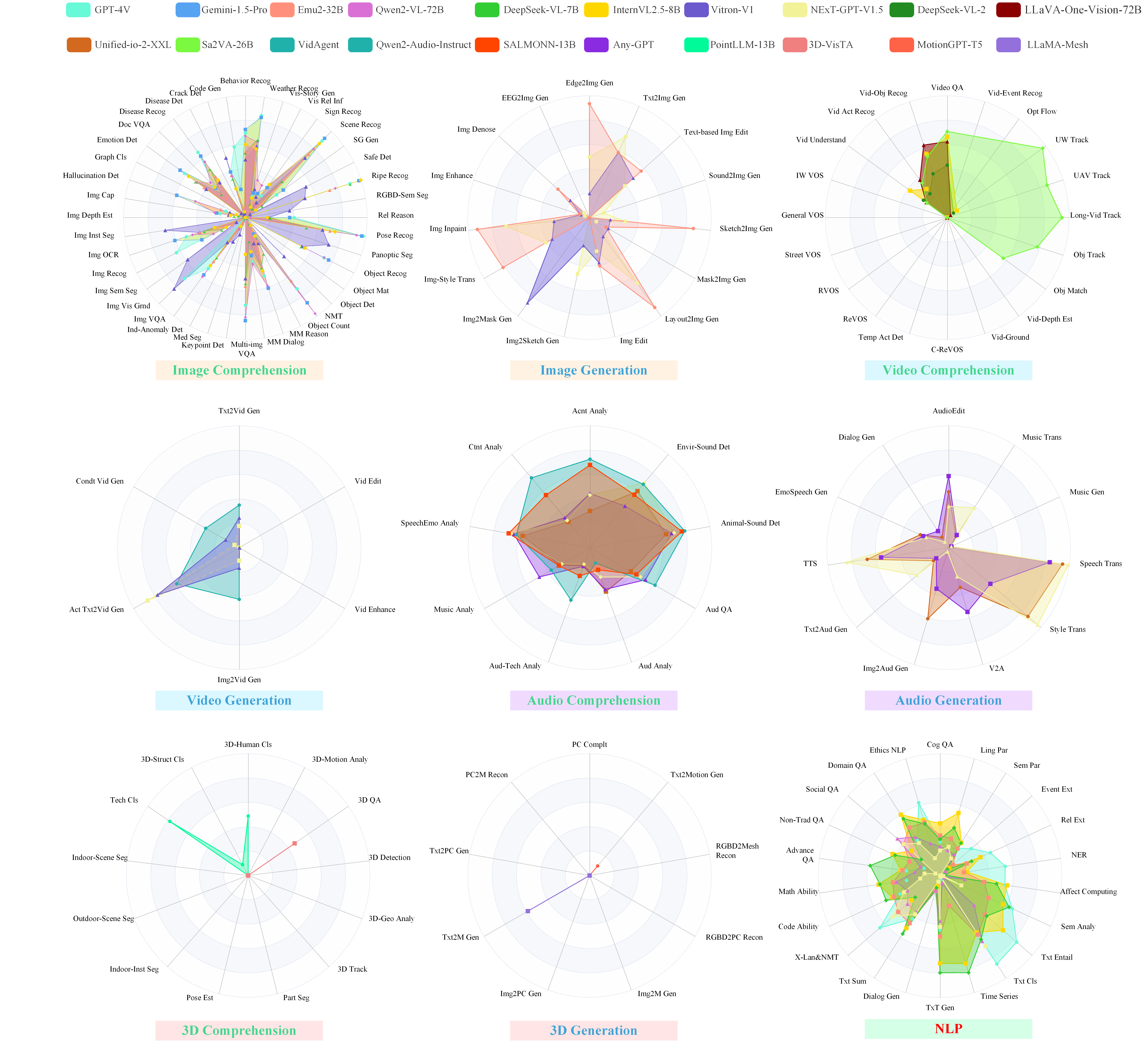
📢 Synergy Analysis - Synergy Across Skills
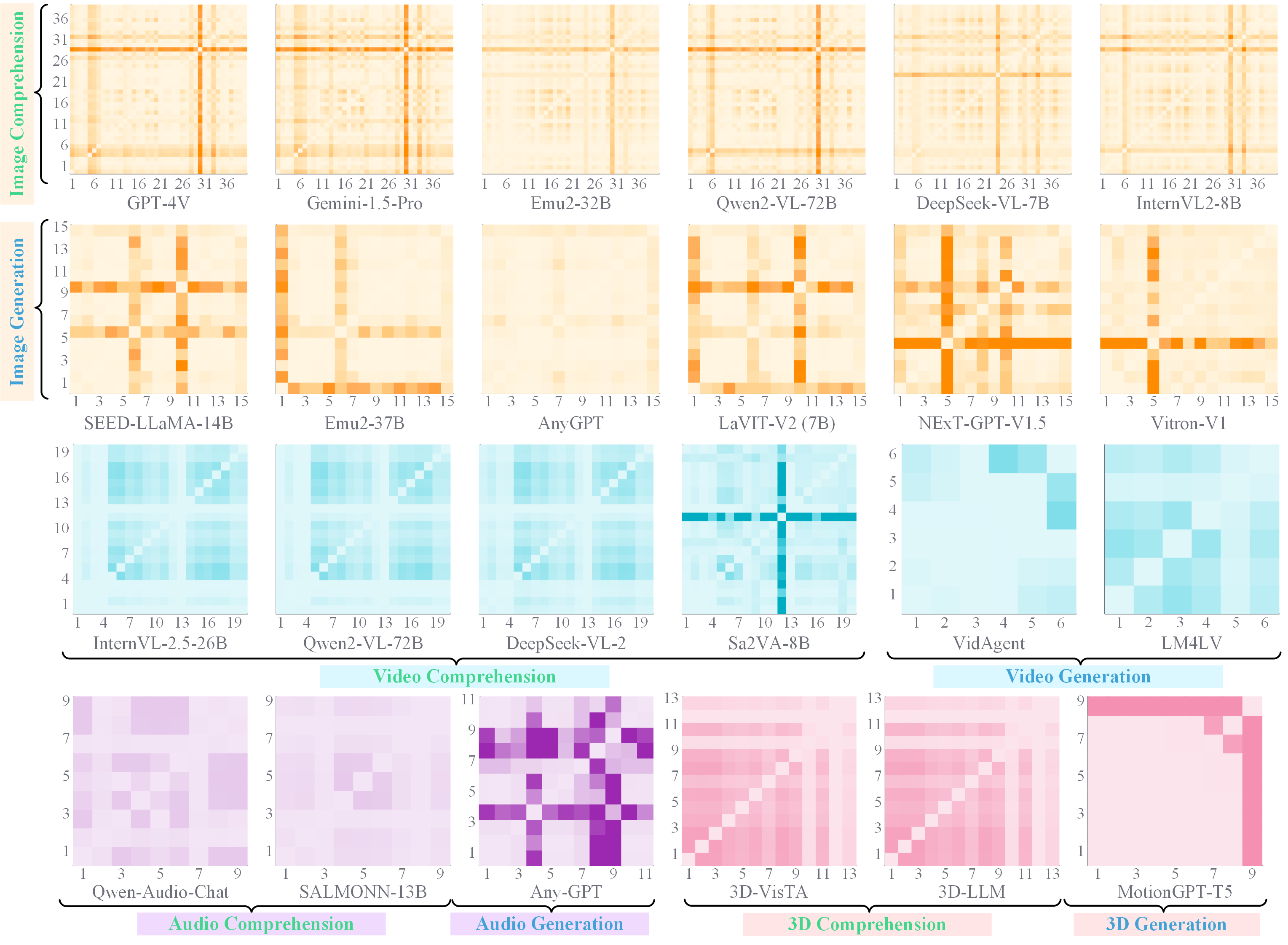
🧪 Capability BreakDown - Modality Supporting
📢 Synergy Analysis - Synergy Across Modalities
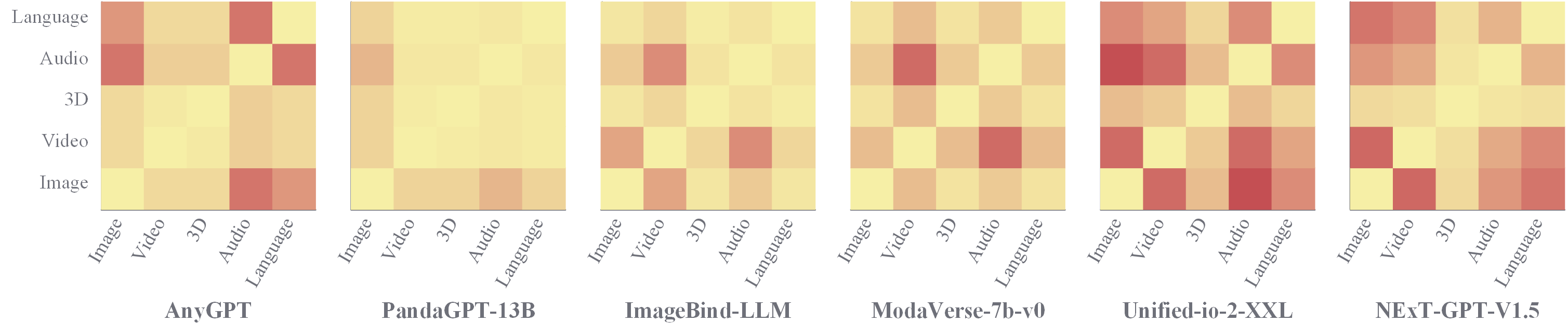
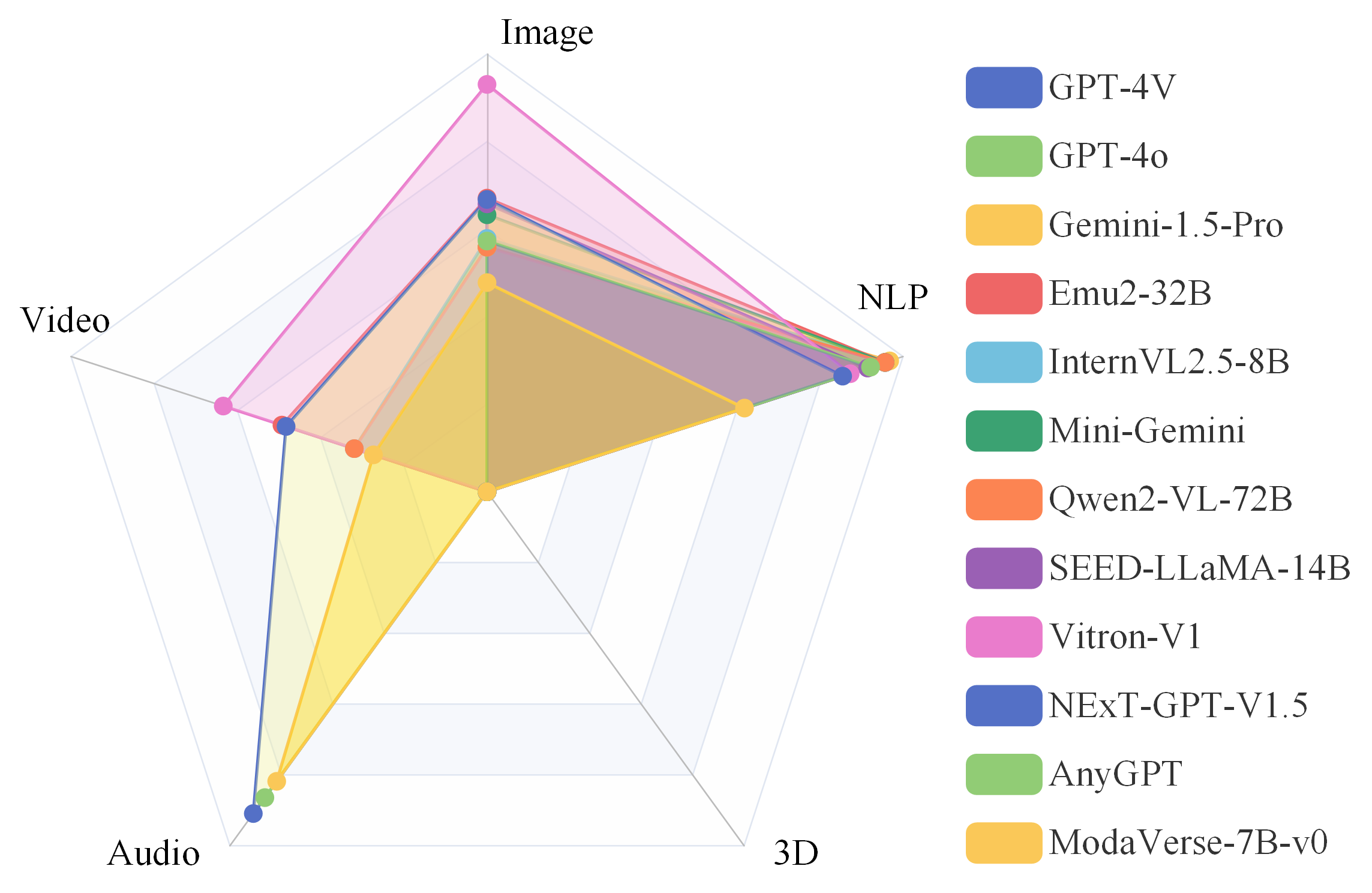
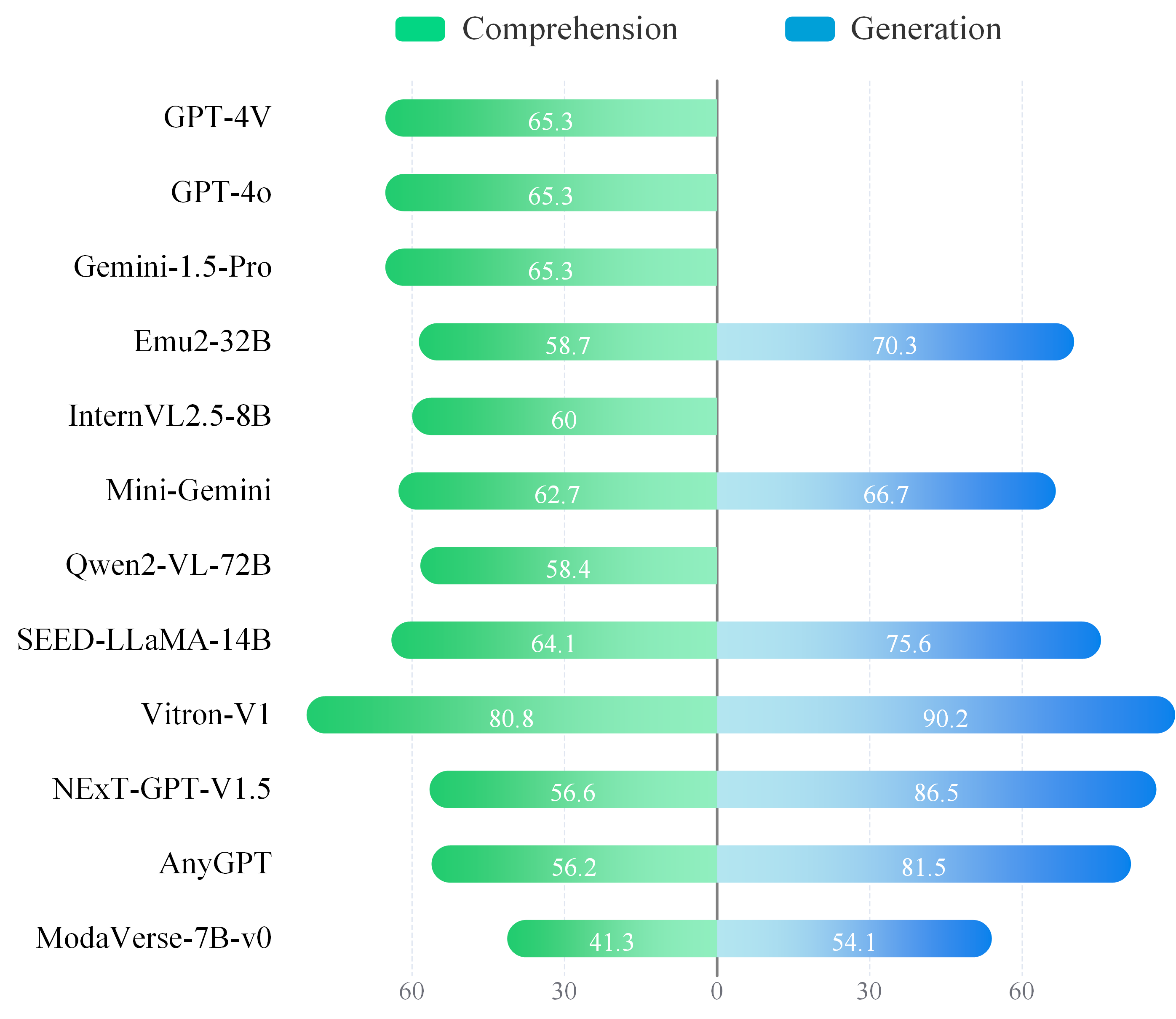
🧪 Capability BreakDown - Capabilities on Comprehension vs. Generation
📢 Synergy Analysis - Synergy Across Comprehension and Generation